
データ解析を始めると、すぐに壁にぶつかります。「t検定を使えばいい?それとも分散分析?ノンパラメトリック検定が必要?」という判断です。目的とデータの条件を整理すれば、使うべき手法は自然に絞れます。このページをブックマークして、迷ったときの判断の起点として使ってください。
🧭 検定の選び方 早わかりフローチャート
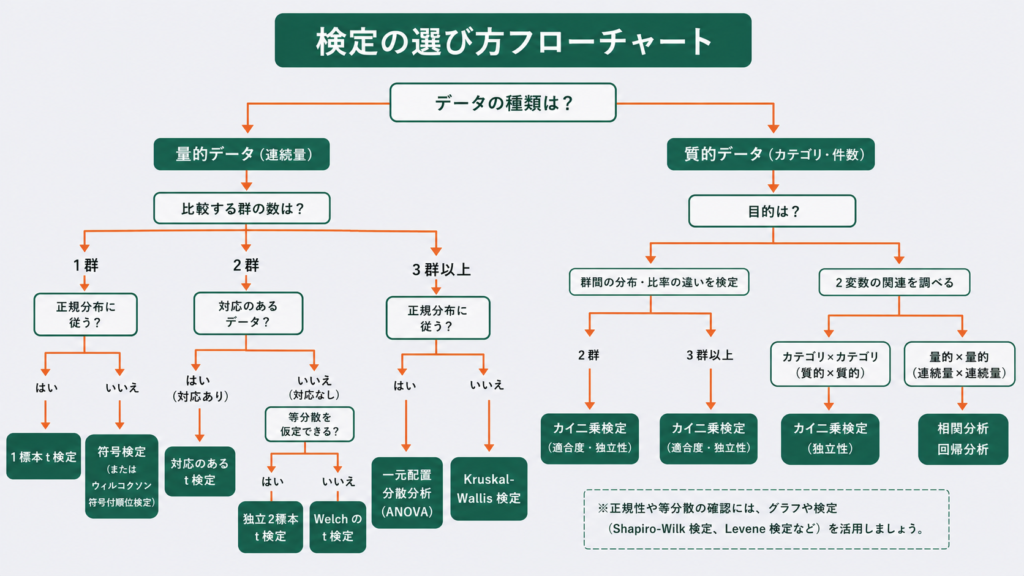
まず「データの種類」から下に向かってたどると、使う検定にたどり着きます。各検定名はクリックで解説記事へ移動します。
STEP1 データは何を測っている?
- 計量値(長さ・強度・収率など連続した数値)→ STEP2へ
- 計数値(個数・良/不良・比率などカテゴリ)→ 母比率の検定/カイ二乗検定
- 2変数の関係を見たい → 相関分析と回帰分析の使い分け
STEP2 比べるグループはいくつ?
- 1群(基準値と比較)→ 1標本t検定(t検定とは)
- 2群 → STEP3へ
- 3群以上 → STEP4へ
STEP3 2群:対応とデータの形は?
- 独立・正規分布 → スチューデントのt検定(分散が違えばウェルチのt検定)
- 対応あり(同一対象の前後)・正規分布 → 対応のあるt検定
- 正規分布でない → ウィルコクソン順位和検定(対応ありは符号順位検定)
STEP4 3群以上:要因とデータの形は?
※ このフローチャート・下の判定表は、出典として本ページへのリンクを添えていただければ、社内資料・授業・ブログ等でご自由に引用いただけます。
検定の選び方 判定マトリクス(一覧表)
条件から逆引きできる一覧表です。「データの種類・群の数・対応・分布」の4つが決まれば、使う検定が1つに絞れます。
| 目的 | 条件 | 使う検定 |
|---|---|---|
| 基準値と比べる | 1群・正規 | 1標本t検定 |
| 2群の平均を比べる | 独立・正規(等分散) | スチューデントのt検定 |
| 独立・正規(分散不等) | ウェルチのt検定 | |
| 2群(対応あり)の平均 | 同一対象の前後・正規 | 対応のあるt検定 |
| 2群(非正規) | 独立 | ウィルコクソン順位和検定 |
| 対応あり | ウィルコクソン符号順位検定 | |
| 3群以上の平均 | 要因1つ・正規 | 一元配置分散分析+多重比較 |
| 3群以上・2要因 | 正規(繰り返しあり) | 繰り返しのある二元配置分散分析 |
| 3群以上(非正規) | 独立 | クラスカル・ウォリス検定 |
| 対応あり | フリードマン検定 | |
| 比率・度数を比べる | 計数値 | 母比率の検定/カイ二乗検定 |
| 分散(ばらつき)を比べる | 2群の分散 | F検定 |
| 2変数の関係を見る | 連続データ | 相関分析・回帰分析 |
表を使う前に、前提となる「分布の形」と「等分散かどうか」の確認が必要です。正規性はシャピロ・ウィルク検定、等分散性はルビーン検定で確かめます。判定に迷ったら、まずこの2つで前提をチェックしてください。
用語や公式をまとめて見たいときは統計・実験計画法の用語と公式まとめも活用できます。
検定を選ぶときに確認する3つのポイント
手法選択に必要な情報は3つだけです。
1つ目は比較するグループの数。2グループか、3グループ以上かで使う手法が変わります。
2つ目はデータの対応関係。同じ対象を2回測定した(改善前・改善後など)「対応あり」のデータか、別々のサンプルを測定した「対応なし」のデータかを確認します。
3つ目は正規性と等分散性。シャピロウイルク検定で正規性を、ルビーン検定で等分散性を確認します。これが成立するかどうかで、パラメトリック検定かノンパラメトリック検定かが決まります。
検定手法を選んだら、実験前に必要なサンプル数も計算しておきましょう。サンプルサイズの決め方|t検定・分散分析に必要なn数で手順を解説しています。
検定手法の選び方フローチャート
テキストでも確認できるよう、フローを以下にまとめます。
2グループを比較する場合
| 対応 | 正規性 | 等分散性 | 使う手法 |
|---|---|---|---|
| あり | あり | — | 対応のあるt検定 |
| あり | なし | — | ウイルコクソンの符号順位和検定 |
| なし | あり | あり | スチューデントのt検定 |
| なし | あり | なし | ウェルチのt検定 |
| なし | なし | — | ウイルコクソンの順位和検定 |
2グループ比較で迷ったときは、ウェルチのt検定を使う、と決めてしまうのも実務的な選択です。スチューデントのt検定は等分散を仮定しますが、ウェルチはその仮定が不要なので、等分散かどうか確認せずに済みます。
3グループ以上を比較する場合
| 対応 | 正規性 | 使う手法 | 有意差後の多重比較 |
|---|---|---|---|
| なし | あり | 一元配置分散分析 | Tukey HSD / ボンフェローニ / ホルム |
| なし | なし | クルスカルワリス検定 | Dunnの多重比較 |
| あり | あり | 反復測定分散分析 | 対応あり多重比較 |
| あり | なし | フリードマン検定 | Dunnの多重比較(対応あり版) |
分散分析で有意差が出ても「どのグループ間に差があるか」はわかりません。どのペアに差があるかを調べるには多重比較法が必要です。比較するグループが3〜5つならTukey HSDが使いやすく、グループ数が多い場合や検出力を重視する場合はホルム補正が向いています。
複数の要因がある場合
「温度と原料の2つの要因を同時に調べたい」など、要因が2つ以上ある実験では分析手法が変わります。
| 要因数 | 手法 | 特徴 |
|---|---|---|
| 2要因 | 二元配置分散分析 | 交互作用(要因の組み合わせ効果)を検出できる |
| 3要因以上・効率重視 | 実験計画法(直交表) | 実験回数を減らして多要因を評価 |
| 最適条件を求めたい | 応答曲面法(RSM) | 要因と応答の関係を曲面でモデル化、最適値を探索 |
「正規性の確認」をどこで実施するか
フローチャートに「正規性あり?」という分岐があります。確認の手順は以下の通りです。
まずシャピロウイルク検定をグループごとに実施します。p値が0.05を超えれば「正規性あり」として進めます。Pythonなら scipy.stats.shapiro() 一行です。
次に等分散性をルビーン検定で確認します(3グループ以上の比較時)。p値が0.05を超えれば「等分散あり」として一元配置分散分析に進めます。Pythonなら scipy.stats.levene() です。
サンプルサイズが大きい(n ≧ 30 程度)場合は、中心極限定理の効果でパラメトリック検定がある程度ロバストに機能します。ヒストグラムや Q-Q プロットで視覚的に確認するだけで十分な場面も多いです。
Pythonで検定を選ぶ際のコード雛形
前提確認から検定まで、2グループ比較のコード例です。
from scipy import stats
# データ
group_a = [52, 55, 53, 49, 56, 58, 54]
group_b = [48, 51, 47, 53, 50, 46, 52]
# Step 1: 正規性確認(各グループ)
_, p_a = stats.shapiro(group_a)
_, p_b = stats.shapiro(group_b)
is_normal = (p_a > 0.05) and (p_b > 0.05)
# Step 2: 等分散性確認
_, p_lev = stats.levene(group_a, group_b)
is_equal_var = p_lev > 0.05
# Step 3: 手法を選択して検定
if is_normal:
if is_equal_var:
stat, p = stats.ttest_ind(group_a, group_b, equal_var=True)
method = "スチューデントのt検定"
else:
stat, p = stats.ttest_ind(group_a, group_b, equal_var=False)
method = "ウェルチのt検定"
else:
stat, p = stats.mannwhitneyu(group_a, group_b, alternative='two-sided')
method = "ウイルコクソンの順位和検定"
print(f"使用手法: {method}")
print(f"統計量 = {stat:.4f}, p値 = {p:.4f}")
このコードをテンプレートとして手元に置いておくと、前提確認から検定まで迷わず進められます。
まとめ:迷ったときの判断軸
「どの検定を使うか」で迷ったときは、グループ数 → 対応あり/なし → 正規性の順に確認すれば答えが出ます。正規性が怪しければノンパラメトリック検定に切り替え、分散分析で有意差が出たら多重比較法に進む、という流れが基本です。
最初はフローチャートを見ながら確認する作業が面倒に感じるかもしれませんが、慣れてくると「このデータはクルスカルワリスだな」と直感で判断できるようになります。それまでこのページを都度参照してください。
各手法の詳しい計算手順や例題は、表内のリンクから確認できます。また、統計学の学習順序が知りたい場合は学習ロードマップも参考にしてください。
2変数間の関連を確認する場合は相関分析を使いますが、得られた相関係数が偶然でないかをt検定で確かめる方法もあります。詳しくは相関係数の有意性検定を参照してください。
カテゴリデータ(合否・分類)の検定にはカイ二乗検定(χ²検定)を使います。工程別の不良率比較や不良種類の偏り検定など、製造業での活用例を例題で解説しています。
各検定で出力されるp値の意味と有意水準0.05の根拠を確認したい場合は、p値とは|有意差の意味と0.05の根拠をわかりやすく解説も合わせてご覧ください。
複数の説明変数を同時に扱う手法(重回帰・ロジスティック回帰・主成分分析・クラスター分析など)は多変量解析として体系化されています。手法ごとの使い分けは多変量解析とは|手法の選び方と9種類を目的別に整理を参照してください。
母分散そのものを検定・推定したい場合は母分散の検定・推定が対応します。
検定統計量がどの分布に従うか(平均はt、分散はχ²、分散比はF)を整理したχ²・t・F分布の使い分けも参考になります。

