ライン管理のミーティングで「ばらつきが大きい」と言われたとき、その「ばらつき」を数字で示せるかどうかが分かれ目になる。感覚ではなく、データで語るための基本指標が標準偏差と分散です。
この記事では、引張強度の測定データを例に、標準偏差と分散の計算手順をゼロから説明します。標本と母集団の違い、ExcelのSTDEV関数の使い分け、変動係数と68-95-99.7ルールまで一通りまとめます。
標準偏差・分散とは
分散と標準偏差は、データが平均からどれだけ散らばっているかを表す指標です。
分散(Variance)は各データと平均の差(偏差)を二乗して平均したもの。二乗しているので単位が元データの2乗になります(MPaのデータならMPa²)。
標準偏差(Standard Deviation)は分散の平方根で、元のデータと同じ単位になります。「データのばらつきを元の単位で表したい」ときは標準偏差を使います。
標準偏差が小さいほど、データが平均の近くに集まっている。大きいほど、散らばりが大きい。それだけです。
標本標準偏差と母標準偏差——どちらを使うか
標準偏差には「標本標準偏差」と「母標準偏差」の2種類があります。式の違いは分母の1つだけですが、使う場面が明確に異なります。
| 種類 | 記号 | 分母 | Excel関数 | 使う場面 |
|---|---|---|---|---|
| 標本標準偏差 | s | n − 1 | =STDEV.S() | 工程から抜き取ったサンプルを分析するとき(通常はこちら) |
| 母標準偏差 | σ | n | =STDEV.P() | 全数データが手元にあるとき(工程全体・ロット全数) |
製造現場で測定データを取るのは「工程のばらつきを推定するため」がほとんどです。抜き取ったサンプルから母集団のばらつきを推定するので、原則として標本標準偏差(STDEV.S)を使います。
分母が n − 1 になる理由は「不偏推定」と呼ばれる統計的な補正によるもので、サンプルから母集団のばらつきを過小評価しないための仕組みです。
計算式
まず偏差平方和(SS)を求め、それを n − 1 または n で割ります。\[ \bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i \] \[ SS = \sum_{i=1}^{n} (x_i – \bar{x})^2 \] \[ s^2 = \frac{SS}{n-1}, \quad s = \sqrt{s^2} \quad \text{(標本分散・標本標準偏差)} \] \[ \sigma^2 = \frac{SS}{n}, \quad \sigma = \sqrt{\sigma^2} \quad \text{(母分散・母標準偏差)} \]
例題:引張強度10件の計算
ある工程ラインで部品の引張強度(MPa)を10個抜き取り測定しました。
498, 501, 503, 497, 502, 500, 504, 499, 501, 502
Step 1:平均を求める
\[ \bar{x} = \frac{498 + 501 + 503 + 497 + 502 + 500 + 504 + 499 + 501 + 502}{10} = \frac{5007}{10} = 500.7 \text{ MPa} \]
Step 2:偏差平方和(SS)を求める
各データから平均を引いて二乗し、合計します。
| データ xᵢ | 偏差 xᵢ − x̄ | 偏差² (xᵢ − x̄)² |
|---|---|---|
| 498 | −2.7 | 7.29 |
| 501 | 0.3 | 0.09 |
| 503 | 2.3 | 5.29 |
| 497 | −3.7 | 13.69 |
| 502 | 1.3 | 1.69 |
| 500 | −0.7 | 0.49 |
| 504 | 3.3 | 10.89 |
| 499 | −1.7 | 2.89 |
| 501 | 0.3 | 0.09 |
| 502 | 1.3 | 1.69 |
| 合計 | 0.0 | 44.10 |
偏差の合計は必ず 0 になります(定義上そうなる)。偏差の合計がゼロにならない場合は計算ミスです。
Step 3:標本分散・標本標準偏差を求める
\[ s^2 = \frac{44.10}{10 – 1} = \frac{44.10}{9} = 4.9000 \text{ MPa}^2 \] \[ s = \sqrt{4.9000} = 2.2136 \text{ MPa} \]
Step 4:母分散・母標準偏差を求める(参考)
\[ \sigma^2 = \frac{44.10}{10} = 4.4100 \text{ MPa}^2 \] \[ \sigma = \sqrt{4.4100} = 2.1000 \text{ MPa} \]
分母が n か n − 1 かで約5%の差が出ます。n が小さいほど差は大きくなります。
Excelでの計算手順
データをA2:A11に入力した場合、以下の関数で各指標を計算できます。
| 指標 | Excel関数 | 結果 |
|---|---|---|
| 平均 | =AVERAGE(A2:A11) | 500.7 |
| 標本標準偏差(通常はこちら) | =STDEV.S(A2:A11) | 2.2136 |
| 母標準偏差 | =STDEV.P(A2:A11) | 2.1000 |
| 標本分散 | =VAR.S(A2:A11) | 4.9000 |
| 母分散 | =VAR.P(A2:A11) | 4.4100 |
古いExcelでは STDEV(STDEV.Sと同じ)と STDEVP(STDEV.Pと同じ)が使われます。Excel 2010以降は .S / .P 形式が正式名称です。
変動係数(CV)——ばらつきの相対比較
標準偏差は「同じ単位のデータ」しか比べられません。引張強度(MPa)と重量(g)のばらつきを比較したいとき、単純に標準偏差の大小を見ても意味がありません。
変動係数(Coefficient of Variation)は標準偏差を平均で割った無次元の指標で、単位の異なるデータのばらつきを比べるときに使います。\[ CV = \frac{s}{\bar{x}} \times 100 \; (\%) \]
例題の場合:\[ CV = \frac{2.2136}{500.7} \times 100 = 0.44\% \]
CV が 0.44% というのは、ばらつきが平均の 0.44% 程度に収まっているという意味です。工程能力の評価や複数工程のばらつき比較で使います。
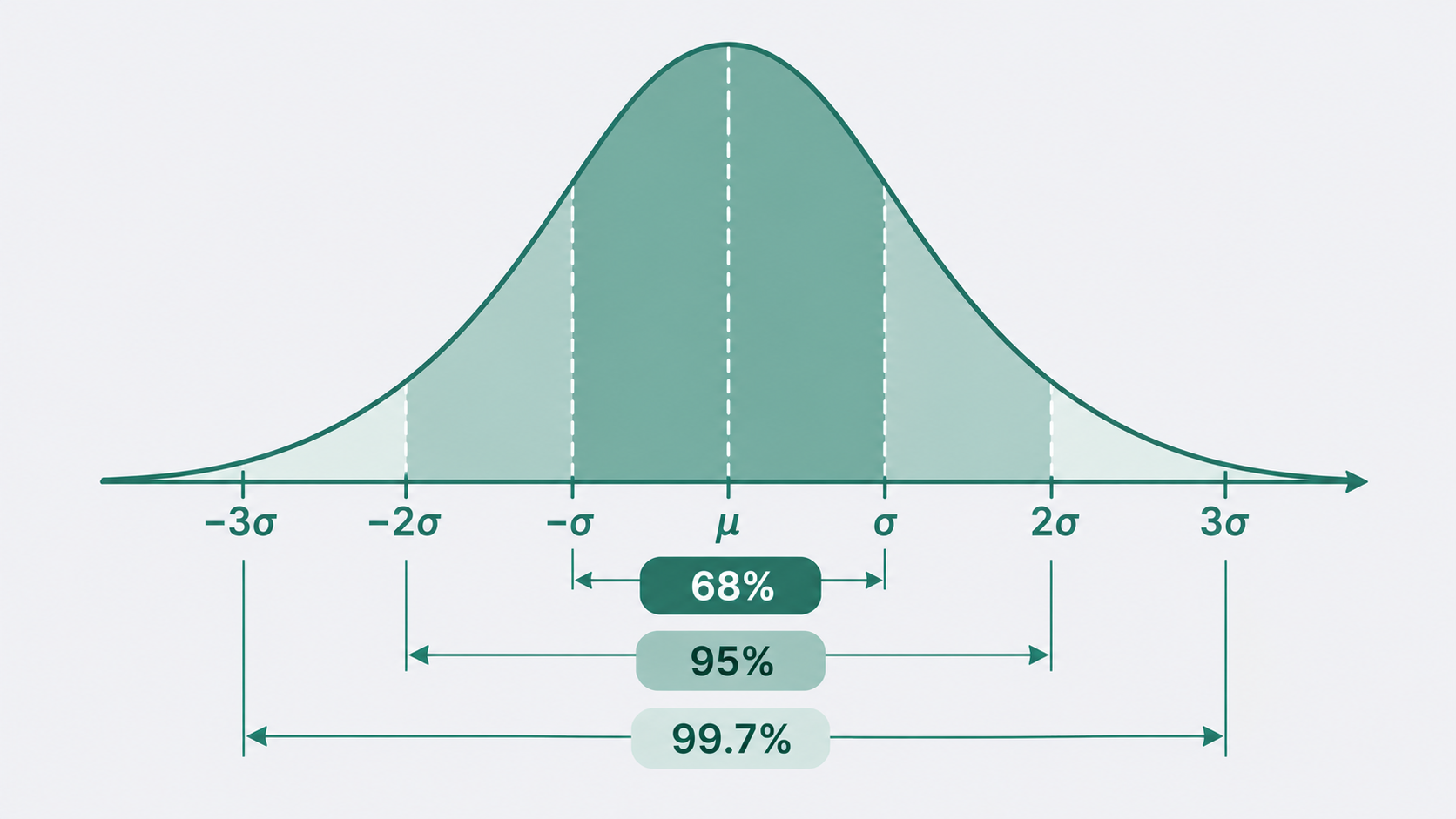
68-95-99.7ルール(正規分布との関係)
データが正規分布に従う場合、平均 ± k × s の範囲にどれだけのデータが含まれるかは理論値として決まっています。
| 範囲 | 含まれる割合 | 例題の区間(MPa) |
|---|---|---|
| x̄ ± 1s | 約68% | [498.49, 502.91] |
| x̄ ± 2s | 約95% | [496.27, 505.13] |
| x̄ ± 3s | 約99.7% | [494.06, 507.34] |
この法則は、管理図の管理限界(UCL・LCL = x̄ ± 3s)の根拠でもあります。3σ外のデータが出る確率は約0.3%——1000回に3回しか起きないような値が出たら、偶然ではなく何か原因があると考える、という判断基準になっています。
管理図の設計と読み方はX-R管理図の作り方と見方を参照してください。
標準偏差の次に使う指標
標準偏差を計算したら、次のステップで活用できます。
データの分布の形(正規性)を視覚的に確認したい場合はヒストグラムを作るやり方、または箱ひげ図(Excelで箱ひげ図を作る方法)が便利です。分布が正規分布に従うかを統計的に判定したい場合はシャピロウイルク検定を使います。
工程能力として定量評価するなら、平均と標準偏差から Cp・Cpk を計算します。詳細は工程能力指数(Cp・Cpk)の計算とExcelでの求め方にまとめています。
2つの工程の平均に差があるかを検定したい場合は、標準偏差をそのまま使ってt統計量を計算します(t検定とは?)。
📚 合わせて読みたい書籍
マンガでわかる統計学(高橋 信)— 正規分布・標準偏差・相関をマンガで直感的に理解できます。統計が苦手な方の入口に。
まとめ
標準偏差・分散の計算手順を整理します。
- 偏差平方和 SS = Σ(xᵢ − x̄)² を求め、n − 1 で割ると標本分散(s²)、平方根が標本標準偏差(s)
- n で割ると母分散(σ²)、平方根が母標準偏差(σ)
- Excelは通常
=STDEV.S()を使う。全数データのときだけ=STDEV.P() - 変動係数 CV = s ÷ x̄ × 100(%)で、単位の異なるばらつきを比較できる
- 正規分布に従う場合、x̄ ± 3s の範囲に99.7%のデータが入る(管理限界の根拠)
標準偏差の計算が身についたら、次は正規分布との関係を掘り下げると理解が深まります。
標準偏差は同じ単位・同じスケールのデータのばらつきを表しますが、単位や平均値が異なる工程を比較したい場合は変動係数(CV)を使います。CVの計算方法と使いどころは変動係数(CV)の求め方と使い方で解説しています。