
この記事でわかること
- 繰り返し測定分散分析の計算手順(変動分解・ANOVA表・F値の読み方)
- 一元配置分散分析との違いと使い分け基準
- Excelのデータ分析ツール「繰り返しなしの二元配置」で実施する手順
📌 前提知識:一元配置分散分析の基本を理解しておくと理解が早くなります
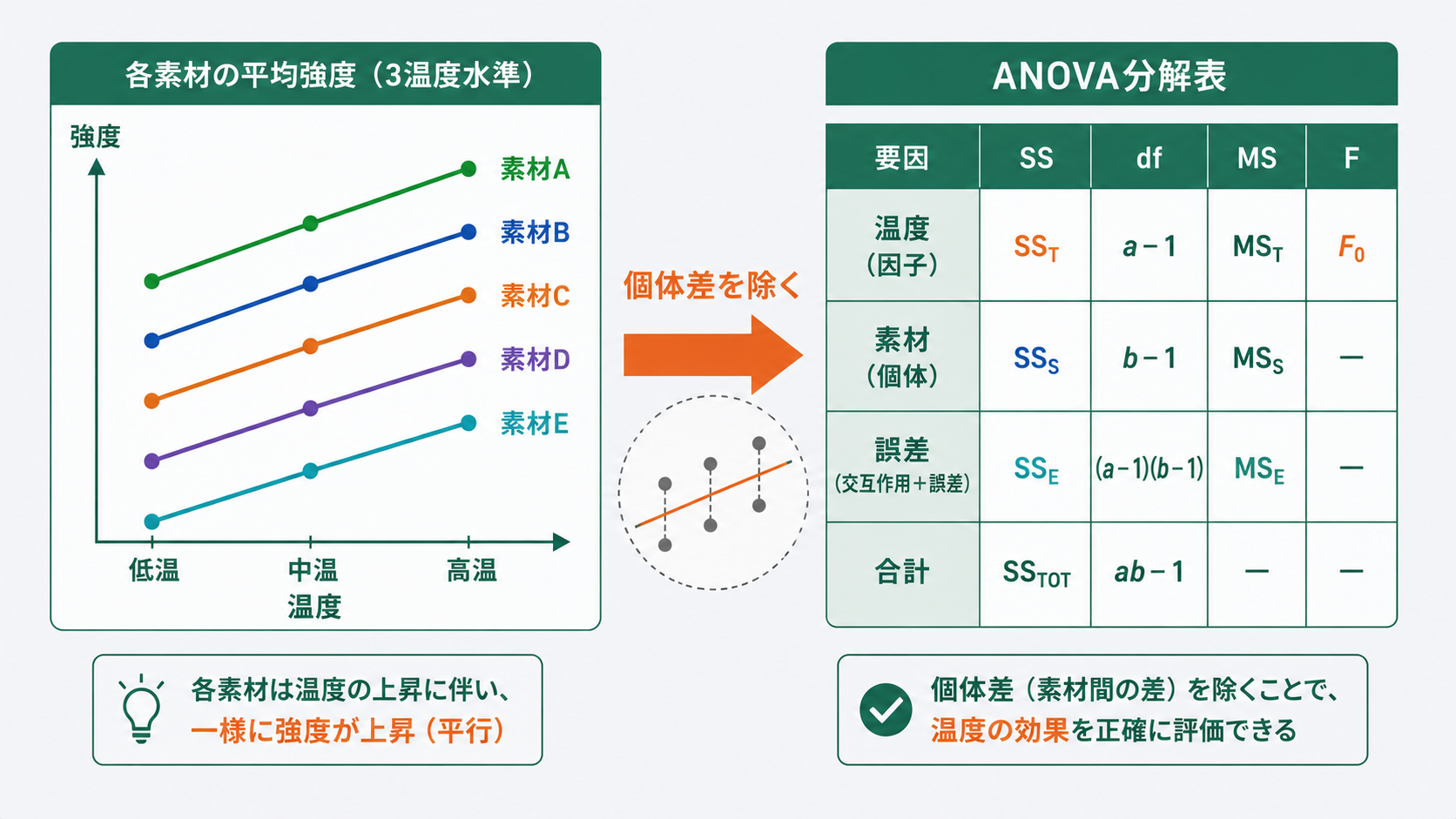
焼入れ温度が硬度に与える影響を調べたい。ただし、素材ロットによってベースの硬度が異なる。3水準の温度を5種類の素材で評価したとき、単純に一元配置分散分析を使うと素材の個体差が誤差に混入し、温度の効果が見えにくくなります。
そんな場面で使うのが繰り返し測定分散分析(repeated measures ANOVA)です。同一の対象(素材・作業者・試験体)を複数条件で繰り返し測定したデータを解析する手法で、個体差を変動として明示的に取り出すことで誤差を小さくし、処理効果の検出力を上げます。
この記事では焼入れ温度と硬度のデータ(素材5種×温度3水準)を例に、計算手順とExcelでの実施方法を解説します。
繰り返し測定分散分析を使う3つの場面
①同一個体を複数条件で評価するとき
最も基本的な使い方です。「同じ素材を異なる温度で処理して特性を比較する」「同じ作業者が複数の工具を使って作業時間を測定する」など、同一の実験単位がすべての処理水準を経験するデザインに使います。
②個体差が大きくサンプル数が少ないとき
素材ロット間のベース硬度のバラツキが大きいなど、個体差が誤差を支配しているケースで特に効果的です。一元配置分散分析では個体差が誤差に混入しますが、繰り返し測定では個体差を明示的に分離します。その結果、残差 $MS_E$ が小さくなり、F 値が上がります。小さいサンプル数でも処理効果を検出しやすくなるのが大きなメリットです。
③ブロック計画として使うとき
繰り返し測定分散分析の構造は、「被験者(素材)をブロック因子とした二元配置分散分析(繰り返しなし)」と同じです。Excelでもこの名称(分散分析: 繰り返しなしの二元配置)で実行できます。
一元配置分散分析との違い
一元配置分散分析では変動を2つに分解します。
$$SS_{\text{全体}} = SS_{\text{処理}} + SS_{\text{誤差(群内)}}$$
繰り返し測定分散分析では、群内変動をさらに「個体差」と「残差」に分けます。
$$SS_{\text{全体}} = SS_{\text{処理}} + SS_{\text{個体}} + SS_{\text{残差}}$$
個体差を誤差から除くことで $MS_{\text{残差}}$ が小さくなり、F 値 $= MS_{\text{処理}} / MS_{\text{残差}}$ が大きくなります。計算にはExcel関数を直接使う方法がなく、データ分析ツールの「分散分析: 繰り返しなしの二元配置」を使います(H2④で手順を説明します)。
出力での対応:行(Rows)= 個体間変動、列(Columns)= 処理間変動、誤差(Error)= 残差 です。
計算手順——焼入れ温度と硬度の例題
使用データ
5種類の素材(n=5)を3水準の焼入れ温度(800℃・850℃・900℃)で処理し、硬度(HRC)を測定しました。各素材は3水準すべてで測定しています。
| 素材 | 800℃ (T1) | 850℃ (T2) | 900℃ (T3) | 素材平均 |
|---|---|---|---|---|
| 1 | 42 | 46 | 50 | 46.0 |
| 2 | 37 | 42 | 44 | 41.0 |
| 3 | 45 | 47 | 53 | 48.3 |
| 4 | 40 | 45 | 47 | 44.0 |
| 5 | 41 | 45 | 51 | 45.7 |
| 温度平均 | 41.0 | 45.0 | 49.0 | 45.0(全体) |
全体平均 $\bar{x}_{..} = 45.0$ HRC。温度が上がるにつれ平均硬度が上昇しています。素材1〜5でベース硬度が 41〜48 HRC と差があり、個体差が大きいデータです。
変動(SS)の計算
処理間変動($SS_A$):温度の効果
$$SS_A = n \sum_{j=1}^{k}(\bar{x}_{.j} – \bar{x}_{..})^2 = 5 \times \left[(41-45)^2 + (45-45)^2 + (49-45)^2\right] = 5 \times 32 = 160.0$$
$n=5$(素材数)、$k=3$(温度水準数)。Excelの出力では「列(Columns)」に対応します。
個体間変動($SS_S$):素材の個体差
$$SS_S = k \sum_{i=1}^{n}(\bar{x}_{i.} – \bar{x}_{..})^2 = 3 \times \left[1^2 + (-4)^2 + 3.3^2 + (-1)^2 + 0.7^2\right] \approx 88.7$$
素材ごとのベース硬度の違いを捉える変動です。Excelの出力では「行(Rows)」に対応します。
全体変動($SS_T$)
$$SS_T = \sum_{i,j}(x_{ij} – \bar{x}_{..})^2 = 258.0 \quad (df = nk – 1 = 14)$$
残差変動($SS_E$)
$$SS_E = SS_T – SS_A – SS_S = 258.0 – 160.0 – 88.7 = 9.3$$
Excelの出力では「誤差(Error)」に対応します。これが F 値の分母になります。
ANOVA 表と判定
| 変動因 | SS | df | MS | F |
|---|---|---|---|---|
| 処理(温度) | 160.0 | 2 | 80.0 | 68.6 ** |
| 個体(素材) | 88.7 | 4 | 22.2 | — |
| 残差 | 9.3 | 8 | 1.2 | — |
| 合計 | 258.0 | 14 | — | — |
$F = MS_A \,/\, MS_E = 80.0 \,/\, 1.2 = 68.6$。F 臨界値(df = 2, 8, $\alpha$ = 0.05)= 4.46 を大きく超えるため、焼入れ温度の効果は有意(** p < 0.01)です。
参考として、同じデータを一元配置分散分析で解析した場合 $F = 9.8$ になります。繰り返し測定分散分析では個体差($SS_S = 88.7$)を誤差から分離したことで、F 値が約 7 倍に上昇しました。
Excelで計算する手順
データの配置
- A列に素材番号(1〜5)、B〜D列に各温度の硬度データを入力する
- 1行目はヘッダー行(「素材」「800℃」「850℃」「900℃」)にする
- データ範囲例:A1:D6(ヘッダー1行 + データ5行)
分散分析の実行
- 「データ」タブ → 「データ分析」をクリックする(表示されない場合:「ファイル」→「オプション」→「アドイン」→「分析ツール」を有効化)
- 「分散分析: 繰り返しなしの二元配置」を選択して OK
- 入力範囲にデータ範囲(A1:D6)を指定する
- 「先頭行をラベルとして使用」にチェックを入れる
- 有意水準を 0.05 のまま OK をクリックする
出力結果の読み方
| Excelの出力表示 | 対応する変動因 | 着目するか |
|---|---|---|
| 行(Rows) | 個体間変動 $SS_S$ | 参考値。素材間の個体差 |
| 列(Columns) | 処理間変動 $SS_A$ | ★ここを確認。処理(温度)の効果 |
| 誤差(Error) | 残差 $SS_E$ | F値の分母 |
「列(Columns)」の行の F 値と P-value(P-value < 0.05 なら有意)を確認します。今回は F = 68.6、P-value ≈ 0.000 となり、焼入れ温度の効果は有意です。
前提条件と事後検定
前提条件の確認
繰り返し測定分散分析を使う前に確認する前提条件は3つあります。
正規性の確認が最初のステップです。各条件のデータが正規分布に従うことが前提で、サンプル数が少ない場合は シャピロ–ウィルク検定で確認します。
条件が3水準以上の場合は球面性(Sphericity)も確認します。すべての条件ペア間の差の分散が等しいという仮定で、Mauchly 検定で評価します。Excelのデータ分析ツールには Mauchly 検定が含まれていないため、球面性が疑われる場合は フリードマン検定(ノンパラメトリック代替)に切り替えるのが実務的な対応です。
独立性については、各素材(被験者)のデータが互いに独立していることを確認します。処理順序の影響(キャリーオーバー効果)がある実験では、処理順序のランダム化が必要です。
有意差があった場合の多重比較
F 検定で有意差が確認できたら、どの水準間に差があるかを多重比較で特定します。繰り返し測定分散分析の事後検定では $MS_E$ を誤差項として使います。今回の例(3水準)では比較ペア数は3なので、ボンフェローニ補正やホルム補正が実施できます。詳しい計算手順は多重比較法の記事を参照してください。
まとめ
繰り返し測定分散分析のポイントを整理します。
- 同一個体を複数条件で測定するデータに使う。個体差を明示的に分離し、処理効果の検出力を上げるのが目的
- 変動の分解:$SS_T = SS_A(処理) + SS_S(個体) + SS_E(残差)$
- 今回の例:一元配置では F = 9.8、繰り返し測定では F = 68.6。個体差(素材ロット差)の除去により約 7 倍に上昇
- Excelは「分散分析: 繰り返しなしの二元配置」で計算できる。「列(Columns)」が処理効果のF値
- 3水準以上では球面性の仮定に注意。Excelで確認できない場合はフリードマン検定が代替手段
使い分けの一言:同一個体を使った実験なら繰り返し測定分散分析、グループ間が独立しているなら一元配置分散分析、2因子を同時に評価するなら二元配置分散分析を選ぶ。
関連記事:

