品質検査で「合格か不合格か」を判定する。あるいは、複数の測定値から製品グレードを自動で分類したい——そういう場面に使えるのが判別分析です。
この記事では、2グループの分類に使う線形判別分析(LDA:Linear Discriminant Analysis)を取り上げます。フィッシャーの線形判別関数の考え方から、Excelで実際に計算する手順まで、製造業の例題をもとに解説します。
判別分析とは
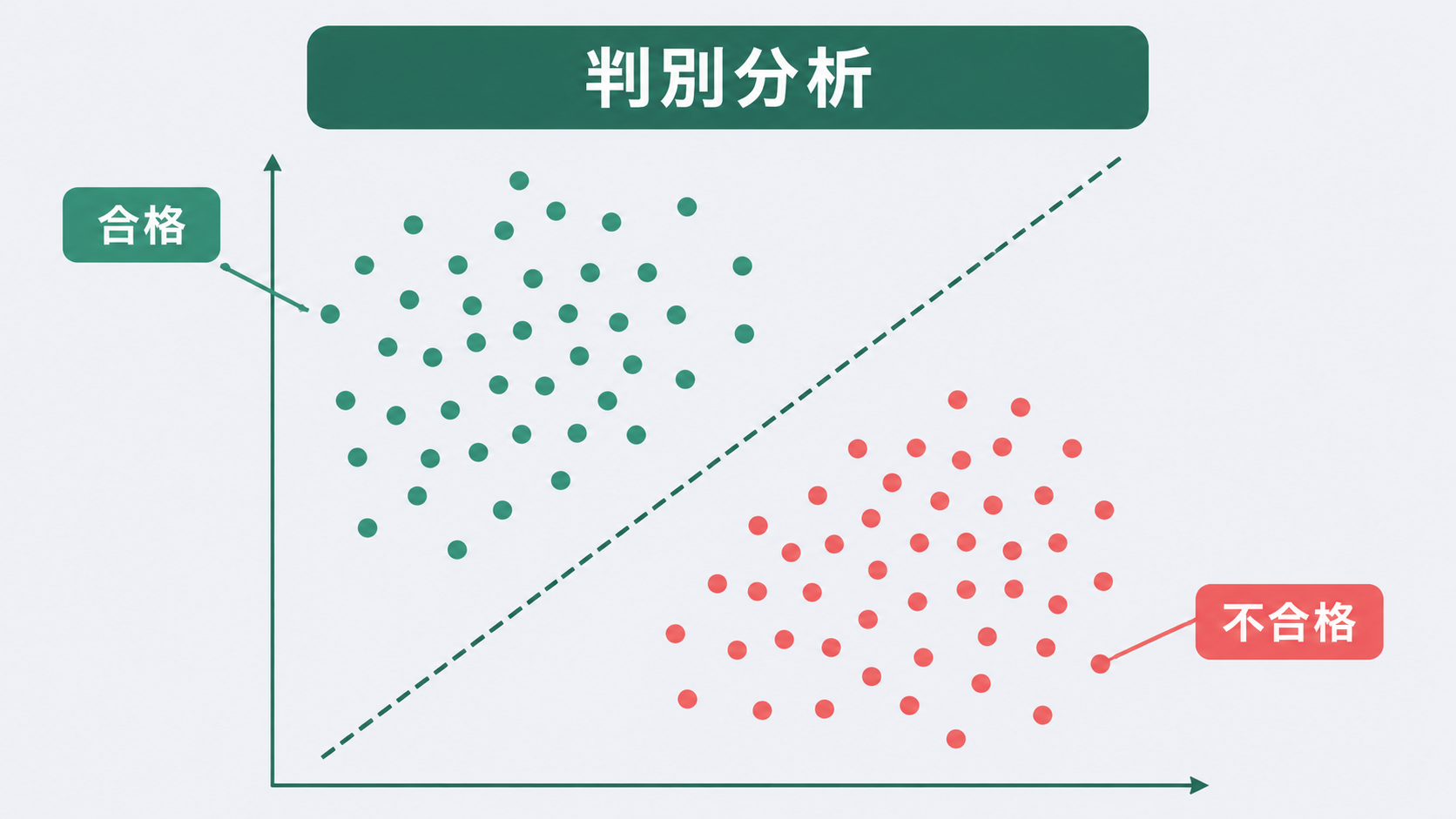
判別分析は、いくつかの変数(説明変数)をもとに、データがどのグループに属するかを判定する手法です。グループの「境界線」を求めることが目的なので、あらかじめグループの正解ラベルが必要です。
ロジスティック回帰と似た目的ですが、アプローチが違います。ロジスティック回帰は確率を予測しますが、判別分析はグループ間の距離を最大化する「判別軸」を直接求めます。
使いどころの目安はこうです。
- グループ数が2つで、各変数が正規分布に近い → 線形判別分析(LDA)
- グループ数が3つ以上 → 多クラスLDA
- グループの境界が非線形 → 二次判別分析(QDA)または機械学習手法
この記事では、最もシンプルな2グループのLDAを扱います。
フィッシャーの線形判別:考え方
LDAの核心は、「グループ間の分離を最大にし、グループ内のばらつきを最小にする」軸を見つけることです。
具体的には、各サンプルに対して\[ z = w_1 x_1 + w_2 x_2 + \cdots + w_p x_p \]
という判別スコアを計算します。\( w_1, w_2, \ldots, w_p \) が判別係数で、この係数の組み合わせを最適化することで、2グループのスコアが最も離れるようにします。
2変数の場合、判別係数ベクトル \( \boldsymbol{w} \) は次の式で求まります。\[ \boldsymbol{w} = \boldsymbol{S}_W^{-1} (\boldsymbol{\mu}_1 – \boldsymbol{\mu}_2) \]
ここで
- \( \boldsymbol{\mu}_1,\, \boldsymbol{\mu}_2 \):各グループの平均ベクトル
- \( \boldsymbol{S}_W \):グループ内散布行列(2グループの合計)
- \( \boldsymbol{S}_W^{-1} \):その逆行列
新しいサンプルの判別スコアが閾値 \( c \) より大きければグループ1、小さければグループ2と判定します。閾値 \( c \) は通常、2グループの重心スコアの中点に設定します。\[ c = \boldsymbol{w}^{\top} \cdot \frac{\boldsymbol{\mu}_1 + \boldsymbol{\mu}_2}{2} \]
例題:プレス部品の合否判別
自動車部品メーカーの品質担当者が、プレス工程のデータを整理しています。過去8ロットについて「硬度(HV)」と「引張強度(MPa)」の2変数を測定し、最終検査で合否が記録されています。
| ロット | 硬度 \( x_1 \)(HV) | 引張強度 \( x_2 \)(MPa) | 判定 |
|---|---|---|---|
| 1 | 205 | 558 | 合格 |
| 2 | 212 | 562 | 合格 |
| 3 | 208 | 552 | 合格 |
| 4 | 215 | 568 | 合格 |
| 5 | 172 | 494 | 不合格 |
| 6 | 168 | 488 | 不合格 |
| 7 | 175 | 498 | 不合格 |
| 8 | 165 | 480 | 不合格 |
このデータから判別関数を求め、新しいロット(硬度=190 HV、引張強度=520 MPa)が合格か不合格かを予測します。
計算手順:ステップごとに追う
Step 1:各グループの平均ベクトルを求める
合格品(ロット1〜4)の平均:\[ \boldsymbol{\mu}_1 = \left( \frac{205+212+208+215}{4},\; \frac{558+562+552+568}{4} \right) = (210,\; 560) \]
不合格品(ロット5〜8)の平均:\[ \boldsymbol{\mu}_2 = \left( \frac{172+168+175+165}{4},\; \frac{494+488+498+480}{4} \right) = (170,\; 490) \]
平均の差:\( \boldsymbol{\mu}_1 – \boldsymbol{\mu}_2 = (40,\; 70) \)
Step 2:グループ内散布行列 \( \boldsymbol{S}_W \) を計算する
各グループで「平均からの偏差」を求め、散布行列を計算します。
合格品の各ロットの偏差:
| ロット | \( x_1 – \mu_{1,1} \) | \( x_2 – \mu_{1,2} \) |
|---|---|---|
| 1 | −5 | −2 |
| 2 | 2 | 2 |
| 3 | −2 | −8 |
| 4 | 5 | 8 |
合格品の散布行列 \( \boldsymbol{S}_1 \):\[ \boldsymbol{S}_1 = \begin{pmatrix} (-5)^2+2^2+(-2)^2+5^2 & (-5)(-2)+2\cdot2+(-2)(-8)+5\cdot8 \\ \cdots & (-2)^2+2^2+(-8)^2+8^2 \end{pmatrix} = \begin{pmatrix} 58 & 70 \\ 70 & 136 \end{pmatrix} \]
不合格品の偏差:
| ロット | \( x_1 – \mu_{2,1} \) | \( x_2 – \mu_{2,2} \) |
|---|---|---|
| 5 | 2 | 4 |
| 6 | −2 | −2 |
| 7 | 5 | 8 |
| 8 | −5 | −10 |
不合格品の散布行列 \( \boldsymbol{S}_2 \):\[ \boldsymbol{S}_2 = \begin{pmatrix} 58 & 102 \\ 102 & 184 \end{pmatrix} \]
グループ内散布行列(合計):\[ \boldsymbol{S}_W = \boldsymbol{S}_1 + \boldsymbol{S}_2 = \begin{pmatrix} 116 & 172 \\ 172 & 320 \end{pmatrix} \]
Step 3:逆行列 \( \boldsymbol{S}_W^{-1} \) を求める
2×2行列の逆行列は次の公式で求めます。\[ \begin{pmatrix} a & b \\ c & d \end{pmatrix}^{-1} = \frac{1}{ad – bc} \begin{pmatrix} d & -b \\ -c & a \end{pmatrix} \]
行列式を計算します。\[ \det(\boldsymbol{S}_W) = 116 \times 320 – 172^2 = 37120 – 29584 = 7536 \]
したがって:\[ \boldsymbol{S}_W^{-1} = \frac{1}{7536} \begin{pmatrix} 320 & -172 \\ -172 & 116 \end{pmatrix} \]
Step 4:判別係数ベクトル \( \boldsymbol{w} \) を計算する
\[ \boldsymbol{w} = \boldsymbol{S}_W^{-1} (\boldsymbol{\mu}_1 – \boldsymbol{\mu}_2) = \frac{1}{7536} \begin{pmatrix} 320 & -172 \\ -172 & 116 \end{pmatrix} \begin{pmatrix} 40 \\ 70 \end{pmatrix} \]
行列とベクトルの積を計算します。\[ \begin{pmatrix} 320 \times 40 + (-172) \times 70 \\ (-172) \times 40 + 116 \times 70 \end{pmatrix} = \begin{pmatrix} 12800 – 12040 \\ -6880 + 8120 \end{pmatrix} = \begin{pmatrix} 760 \\ 1240 \end{pmatrix} \]
判別係数:\[ w_1 = \frac{760}{7536} \approx 0.1008, \quad w_2 = \frac{1240}{7536} \approx 0.1645 \]
判別関数はこうなります。\[ z = 0.1008\, x_1 + 0.1645\, x_2 \]
Step 5:判別閾値 \( c \) を計算する
2グループの重心の中点に閾値を設定します。\[ \boldsymbol{\mu}_{\text{mid}} = \frac{\boldsymbol{\mu}_1 + \boldsymbol{\mu}_2}{2} = \left( \frac{210+170}{2},\; \frac{560+490}{2} \right) = (190,\; 525) \] \[ c = 0.1008 \times 190 + 0.1645 \times 525 = 19.15 + 86.36 = 105.51 \]
スコアが 105.51 より大きければ合格、小さければ不合格と判別します。
Step 6:訓練データで判別スコアを確認する
8ロットすべての判別スコアを計算して正しく分類できているか確認します。
| ロット | 判別スコア \( z \) | 正解 | 判別結果 |
|---|---|---|---|
| 1 | 112.5 | 合格 | 合格 ✓ |
| 2 | 113.9 | 合格 | 合格 ✓ |
| 3 | 111.8 | 合格 | 合格 ✓ |
| 4 | 115.1 | 合格 | 合格 ✓ |
| 5 | 98.6 | 不合格 | 不合格 ✓ |
| 6 | 97.2 | 不合格 | 不合格 ✓ |
| 7 | 99.6 | 不合格 | 不合格 ✓ |
| 8 | 95.6 | 不合格 | 不合格 ✓ |
全8ロットで正しく分類されました。正判別率は 8/8 = 100% です。
ただし、これはあくまで「訓練データ上の精度」です。新しいデータへの汎化性能は、交差検証(leave-one-out など)で確認する必要があります。
Step 7:新しいロットを判別する
硬度=190 HV、引張強度=520 MPa の新規ロットを判別します。\[ z = 0.1008 \times 190 + 0.1645 \times 520 = 19.15 + 85.54 = 104.69 \]
104.69 < 105.51(閾値)なので、不合格と判別されます。
スコアの差は 0.82 とかなり小さく、境界ぎりぎりの判定です。このような場合は、追加測定や工程の確認を行うのが現実的です。
Excelでの実施手順
Excelでは、行列演算の関数(MMULT・MINVERSE)を使うと計算できます。
データ入力と平均の計算
- A列に硬度、B列に引張強度、C列にグループ(1=合格、2=不合格)を入力
- 合格品の平均:
=AVERAGE(A2:A5)、=AVERAGE(B2:B5) - 不合格品の平均:
=AVERAGE(A6:A9)、=AVERAGE(B6:B9)
散布行列と逆行列の計算
- 偏差を計算(例:
=A2-$F$2で合格品の x1 偏差) - 散布行列の各要素を SUMPRODUCT で計算
- \( S_W[1,1] \):
=SUMPRODUCT(偏差x1合格, 偏差x1合格) + SUMPRODUCT(偏差x1不合格, 偏差x1不合格) - \( S_W[1,2] \):
=SUMPRODUCT(偏差x1合格, 偏差x2合格) + SUMPRODUCT(偏差x1不合格, 偏差x2不合格)
- \( S_W[1,1] \):
- 逆行列は配列数式で計算。\( S_W \) が入力されたセル範囲を選択して:
=MINVERSE(SW行列範囲)(Ctrl+Shift+Enter で確定)
判別係数と判別スコアの計算
- 判別係数:
=MMULT(SW逆行列範囲, 平均差ベクトル範囲)(配列数式) - 各ロットの判別スコア:
=SUMPRODUCT(判別係数範囲, データ範囲) - 閾値との比較:
=IF(スコアセル > 閾値, "合格", "不合格")
手順が多いように見えますが、行列の仕組みを理解していれば計算ステップは素直です。主成分分析でも同様の行列演算を使うので、合わせて確認すると理解が深まります。
LDAを使う際の注意点
多変量正規性の前提
LDAは各グループの変数が正規分布に従うことを前提としています。外れ値が多いデータや、変数の分布が大きく歪んでいる場合は精度が落ちることがあります。各変数の分布をヒストグラムで確認してから使うことをおすすめします。
等共分散行列の前提
LDAは2グループで共分散構造が等しいことを前提としています(今回はグループ内散布行列を合算して使いました)。グループ間で分散構造が大きく異なる場合は、二次判別分析(QDA)の方が適しています。
訓練データへの過学習
今回の例は全8ロットで正判別率100%でしたが、これはサンプル数が少ないため楽観的な数字です。実際には leave-one-out 交差検証や独立したテストデータで精度を確認してください。
変数間の多重共線性
硬度と引張強度のように強く相関する変数を複数使うと、\( S_W \) の逆行列が不安定になることがあります。重回帰分析のVIF確認と同様に、変数の選択に注意が必要です。
まとめ
線形判別分析(LDA)の計算手順をまとめます。
- 各グループの平均ベクトル \( \boldsymbol{\mu}_1, \boldsymbol{\mu}_2 \) を求める
- グループ内散布行列 \( \boldsymbol{S}_W = \boldsymbol{S}_1 + \boldsymbol{S}_2 \) を計算する
- 逆行列 \( \boldsymbol{S}_W^{-1} \) を求める(Excelなら MINVERSE)
- 判別係数 \( \boldsymbol{w} = \boldsymbol{S}_W^{-1}(\boldsymbol{\mu}_1 – \boldsymbol{\mu}_2) \) を計算する
- 閾値 \( c = \boldsymbol{w}^\top \boldsymbol{\mu}_{\text{mid}} \) を設定する
- 各サンプルのスコア \( z = \boldsymbol{w}^\top \boldsymbol{x} \) を計算し、閾値と比較する
今回の例では硬度と引張強度の2変数で判別関数を構築し、新しいロット(190 HV・520 MPa)を「不合格に近い状態」として検出できました。変数が3つ以上になっても同じ手順で対応できます。
多変量解析の他の手法との違いをまとめると、主成分分析(PCA)はデータの構造を要約する手法で、グループラベルは使いません。クラスター分析はラベルなしでグループを自動発見します。判別分析は「既知のグループに新しいデータを割り当てる」という用途に特化しています。3つを使い分けることで、多変量データ分析の幅が広がります。
変数の背後にある潜在的な共通構造を把握してから判別分析に臨むと、変数選択の根拠が明確になります。因子分析で次元を整理してから判別関数を構築する流れも多変量解析では定石の一つです。