
製造ラインから上がってくる品質データを眺めていると、「このロット群はなんとなく似ているな」と感じることがあります。その「なんとなく」を数値で裏づけするのがクラスター分析です。
この記事では、硬度・引張強度のデータをもつ10本の鋼材ロットを例に、ウォード法による階層クラスタリングとk-meansの2手法を手順を追って解説します。Excelで距離行列を計算する具体的な関数式も紹介するので、すぐに自分のデータへ応用できます。
クラスター分析とは
クラスター分析(cluster analysis)は、複数の変数をもつデータを「互いに似ているもの同士のグループ(クラスター)」に自動的に分ける手法です。あらかじめグループ数や正解ラベルを与えずに分類できるため、教師なし学習の代表格として位置づけられています。
製造現場では次のような場面で活躍します。
- 複数ロットの品質特性(硬度・引張強度・延性など)から類似ロットをグループ化し、条件ごとの傾向を把握する
- 工程パラメータの組み合わせを類型化して、安定条件と不安定条件を区別する
- 顧客や製品ラインナップの特性パターンを整理し、対応施策を絞り込む
主成分分析(PCA)とよく併用される手法で、PCAで次元を落としてからクラスタリングする流れが実務では多いです。
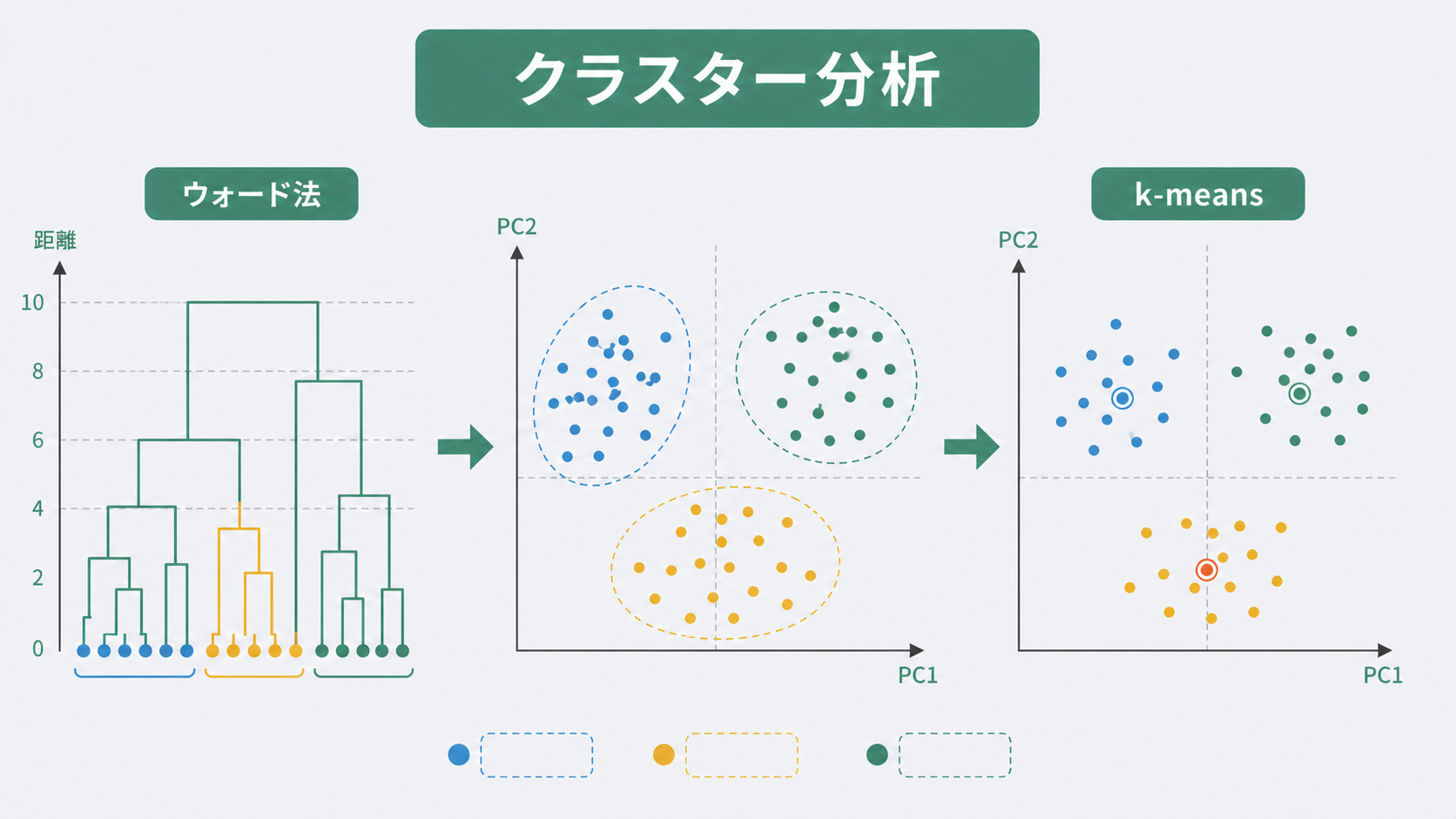
2種類の手法:階層型と非階層型
クラスター分析には大きく分けて2種類あります。
階層型クラスタリングは、最も近い2点(またはクラスター)を順番に結合していき、樹形図(デンドログラム)を描くアプローチです。k数を事前に決めなくていい反面、データ数が増えると計算量が大きくなります。代表的な手法はウォード法(Ward’s method)です。
非階層型クラスタリング(k-means)は、事前にクラスター数kを指定し、各データ点を最近傍の重心に割り当てながら重心を更新していきます。計算が速く大規模データに向いていますが、kを自分で決める必要があります。
どちらかだけを使うより、階層型でデンドログラムを見てkを決め、非階層型で仕上げる——というコンビネーションが現場ではうまく機能します。
例題データ:鋼材ロット10本の品質特性
今回は鋼材ロット10本の品質検査データを使います。変数は硬度(HV)と引張強度(MPa)の2つです。
| ロット | 硬度(HV) | 引張強度(MPa) |
|---|---|---|
| ロット1 | 155 | 480 |
| ロット2 | 160 | 490 |
| ロット3 | 158 | 485 |
| ロット4 | 200 | 560 |
| ロット5 | 195 | 550 |
| ロット6 | 198 | 555 |
| ロット7 | 240 | 620 |
| ロット8 | 245 | 630 |
| ロット9 | 242 | 625 |
| ロット10 | 238 | 615 |
散布図でプロットすると、低硬度群(155〜160 HV)・中硬度群(195〜200 HV)・高硬度群(238〜245 HV)の3つのまとまりが目視でもわかります。クラスター分析がこれを定量的に裏づけできるか確認していきます。
ユークリッド距離の計算
クラスター分析では、「2点がどれだけ離れているか」を距離で測ります。2変数の場合のユークリッド距離は次の式です。\[ d(i, j) = \sqrt{(x_{1i} – x_{1j})^2 + (x_{2i} – x_{2j})^2} \]
ここで \(x_1\) が硬度、\(x_2\) が引張強度です。ロット1とロット2の距離を計算してみます。\[ d(\text{ロット1}, \text{ロット2}) = \sqrt{(155-160)^2 + (480-490)^2} = \sqrt{25 + 100} = \sqrt{125} \approx 11.18 \]
一方、ロット1とロット4(異なるグループ)の距離は大きく跳ね上がります。\[ d(\text{ロット1}, \text{ロット4}) = \sqrt{(155-200)^2 + (480-560)^2} = \sqrt{2025 + 6400} = \sqrt{8425} \approx 91.79 \]
同じグループ内の距離(11.18)と異なるグループ間の距離(91.79)で8倍以上の差があることが、この段階で見えてきます。
距離行列(全10ロット)
全ペアの距離をまとめた距離行列です。対角は0、上三角のみ示します。
| L1 | L2 | L3 | L4 | L5 | L6 | L7 | L8 | L9 | L10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| L1 | 0.00 | 11.18 | 5.83 | 91.79 | 80.62 | 86.45 | 163.78 | 174.93 | 169.10 | 158.47 |
| L2 | — | 0.00 | 5.39 | 80.62 | 69.46 | 75.29 | 152.64 | 163.78 | 157.95 | 147.34 |
| L3 | — | — | 0.00 | 85.96 | 74.79 | 80.62 | 157.95 | 169.10 | 163.27 | 152.64 |
| L4 | — | — | — | 0.00 | 11.18 | 5.39 | 72.11 | 83.22 | 77.39 | 66.85 |
| L5 | — | — | — | — | 0.00 | 5.83 | 83.22 | 94.34 | 88.51 | 77.94 |
| L6 | — | — | — | — | — | 0.00 | 77.39 | 88.51 | 82.68 | 72.11 |
| L7 | — | — | — | — | — | — | 0.00 | 11.18 | 5.39 | 5.39 |
| L8 | — | — | — | — | — | — | — | 0.00 | 5.83 | 16.55 |
| L9 | — | — | — | — | — | — | — | — | 0.00 | 10.77 |
| L10 | — | — | — | — | — | — | — | — | — | 0.00 |
距離行列を見ると、ロット1〜3・ロット4〜6・ロット7〜10の3ブロック内では値が小さく(5〜17程度)、ブロック間では66〜175と大きく跳ね上がっているのがわかります。
ウォード法による階層クラスタリング
ウォード法の考え方
単純に「最も近い2点を結合する」だけでは、細長く歪んだクラスターができやすいという問題があります。ウォード法はこの問題を回避するため、「2つのクラスターを結合したとき、クラスター内平方和(ESS)がどれだけ増えるか」を距離として使います。
2つのクラスター \(A\)・\(B\) を結合したときのESS増加量は次の式で計算します。\[ \Delta SS(A, B) = \frac{n_A \cdot n_B}{n_A + n_B} \cdot \|\bar{x}_A – \bar{x}_B\|^2 \]
\(n_A, n_B\) は各クラスターのサンプル数、\(\bar{x}_A, \bar{x}_B\) は重心ベクトルです。ウォード距離はこの平方根 \(\sqrt{\Delta SS}\) として定義されます。ESS増加を最小にする組み合わせを選んで結合するので、コンパクトで球状に近いクラスターが得られます。
ステップごとの結合過程
10ロットから始めて、毎ステップで最もウォード距離が小さいペアを結合していきます。
Step 1:ロット2とロット3を結合(Ward距離 = 3.81)
ロット2の重心(160, 490)・ロット3の重心(158, 485)として、\[ \Delta SS = \frac{1 \times 1}{1 + 1} \times \left[(160-158)^2 + (490-485)^2\right] = 0.5 \times 29 = 14.5 \] \[ d_W = \sqrt{14.5} \approx 3.81 \]
同じ距離でロット4+ロット6(3.81)、ロット7+ロット9(3.81)も最短なので、Step 2・3でそれぞれ結合されます。
結合過程をまとめると次のとおりです。
| Step | 結合されるクラスター | Ward距離 | クラスタサイズ |
|---|---|---|---|
| 1 | ロット2 + ロット3 | 3.81 | 2 |
| 2 | ロット4 + ロット6 | 3.81 | 2 |
| 3 | ロット7 + ロット9 | 3.81 | 2 |
| 4 | {ロット7, ロット9} + ロット10 | 6.60 | 3 |
| 5 | ロット1 + {ロット2, ロット3} | 6.94 | 3 |
| 6 | {ロット4, ロット6} + ロット5 | 6.94 | 3 |
| 7 | {ロット7, ロット9, ロット10} + ロット8 | 9.68 | 4 |
| 8 | {ロット1,2,3} + {ロット4,5,6} | 98.74 | 6 |
| 9 | {ロット1〜6} + {ロット7〜10} | 186.86 | 10 |
デンドログラムの読み方とクラスタ数の決定
上の結合過程を樹形図(デンドログラム)として描くと、縦軸がWard距離、横軸に各ロットが並びます。
クラスタ数の決め方は、距離の急激なジャンプ(大きな段差)の直前を切り取るのが基本です。今回の結合過程を見ると、
- Step7まで:Ward距離は最大でも9.68
- Step8(低硬度群+中硬度群の結合):一気に98.74へ跳ね上がる
この段差(9.68 → 98.74、増加量89.06)が最大のジャンプです。「Step8の結合を阻止した状態」が最良の分割なので、クラスター数はk = 3と判断できます。
最終的なクラスター構成
| クラスター | メンバー | 重心 硬度(HV) | 重心 引張強度(MPa) | 特徴 |
|---|---|---|---|---|
| クラスター1 | ロット1, 2, 3 | 157.7 | 485.0 | 低硬度・低引張強度群 |
| クラスター2 | ロット4, 5, 6 | 197.7 | 555.0 | 中硬度・中引張強度群 |
| クラスター3 | ロット7, 8, 9, 10 | 241.2 | 622.5 | 高硬度・高引張強度群 |
目視で「なんとなく3グループ」と感じていた直感が、ウォード法で定量的に裏づけられました。
k-meansクラスタリング
アルゴリズムの手順
k-meansはシンプルな繰り返し計算で動作します。
- クラスター数kを決め、初期重心を設定する(ランダムまたは指定)
- 各データ点を最近傍の重心に割り当てる
- 各クラスターの重心を再計算する
- 重心が変化しなくなるまで 2〜3 を繰り返す
例題での適用
k = 3 として、初期重心をロット1(155, 480)・ロット4(200, 560)・ロット7(240, 620)に設定して計算します。今回のデータは初期重心が各グループの代表点に近いため、2回の更新で収束します。
最終的なクラスター割り当てと重心は次のとおりです。
| クラスター | メンバー | 重心 硬度(HV) | 重心 引張強度(MPa) |
|---|---|---|---|
| クラスター1 | ロット1, 2, 3 | 157.7 | 485.0 |
| クラスター2 | ロット4, 5, 6 | 197.7 | 555.0 |
| クラスター3 | ロット7, 8, 9, 10 | 241.2 | 622.5 |
クラスター内平方和(WCSS)は 277.08 で、全10点が正しく3グループに分類されています。
階層クラスタリングと全く同じグループになりました。データの構造がはっきりしているこの例では当然の結果ですが、実際のデータでは2手法の結果が食い違うこともあります。その場合は、どちらの解釈が業務上有意義かを考えて選択します。
k-meansの注意点
k-meansには、初期重心の選び方によって局所最適に陥るリスクがあります。対策として、初期値を変えて複数回実行し、WCSSが最も小さい結果を採用するのが定石です。Pythonのscikit-learnは`n_init=10`(デフォルト)で自動的に10回試行してくれます。
Excelでの実装手順
距離行列の計算
Excelで距離行列を作るには、SQRT関数とSUMXMY2関数を組み合わせます。データをA列(ロット名)・B列(硬度)・C列(引張強度)に入力した場合、距離行列は次のように作ります。
STEP 1:E1セルに「距離行列」と入力し、F1〜O1にロット1〜10の名前を横に並べる。E2〜E11にロット1〜10の名前を縦に並べる。
STEP 2:F2セル(ロット1 vs ロット1の交点)に次の数式を入力します。
=SQRT(SUMXMY2(($B2,$C2),($B$2:$B$11,$C$2:$C$11)))
実際にはSUMXMY2の第2引数は行固定が必要なので、個別セルに分けると安定します。
=SQRT(($B2-F$1_hardness)^2+($C2-F$1_strength)^2)
より確実な書き方は、行ヘッダーに硬度・引張強度の値を参照させる2行式です。F2に入力する基本形は:
=SQRT(($B2-$B3)^2+($C2-$C3)^2)
実際には行番号・列番号を$で固定しながら、比較する2ロットの行を参照します。小規模データ(10〜20ロット)ならこの方法で十分です。
STEP 3:距離行列が完成したら、条件付き書式でセルの背景色をグラデーション表示にします。距離が小さい(近い)ペアが色で一目でわかります。
最小距離ペアの自動検出
上三角行列(i < j の部分)から最小値を見つけるには、MIN関数と目視の組み合わせで十分です。サイズが大きい場合はMATCH関数で行・列番号を特定します。
=MIN(F2:O11) ' 行列全体の最小距離 =MATCH(MIN(F2:O11),F2:F11,0) ' 最小距離の行位置
ウォード法の結合過程をExcelで完全に自動化するのは難易度が高いです。距離行列の作成まではExcelで行い、その後の結合判断は手動で追うか、PythonのSciPyに渡す方法が現実的です。
Pythonで分析する方法については 主成分分析の記事も参考にしてください。
手法の使い分け
階層クラスタリング(ウォード法)とk-meansは目的に応じて使い分けます。
| 比較項目 | 階層クラスタリング(ウォード法) | k-means |
|---|---|---|
| 事前にkを決める必要 | 不要(デンドログラムで後から決める) | 必要 |
| データ規模 | 小〜中規模(数百件まで) | 大規模にも対応 |
| 結果の再現性 | 常に同じ結果 | 初期値依存(複数回実行で対策) |
| クラスターの形 | コンパクト・球状向き | 球状クラスター向き |
| 主な用途 | 探索的分析・k数の探索 | 大量データの分類・繰り返し分析 |
初めて分析するデータなら、まず階層クラスタリングでデンドログラムを描いてkを探る。k が決まったらk-meansで確認する——この順番がもっとも実践的です。
なお、クラスター分析では変数のスケールが大きく異なる場合(硬度が100 HV前後、強度が1000 MPa前後など)、事前に標準化(各変数をz変換)してから距離を計算する必要があります。スケールの大きい変数が距離を支配してしまうためです。相関分析と同様に、変数の単位や分散に注意するのが基本です。
まとめ
クラスター分析の要点を整理します。
- データをあらかじめラベルなしでグループ分けできる手法。探索的分析の入口として有効
- ウォード法(階層型)はデンドログラムで適切なクラスタ数を視覚的に判断できる。距離のジャンプが大きい箇所を切り取る
- k-meansは計算が速く繰り返し分析に向く。初期値依存の問題は複数回実行で回避
- Excelでは距離行列の計算まで対応可能。ウォード法の全自動化はPythonが現実的
- 変数のスケールが異なる場合は標準化してから分析する
今回の鋼材10ロット例では、目視で感じていた3グループの境界が、ウォード距離のジャンプ(9.68 → 98.74)として明確に現れました。「この差は本当に意味があるのか」と悩んでいたときに、こうした数値的な裏づけがあると上司への説明もしやすくなります。
多変量解析のカテゴリでは、主成分分析(PCA)・重回帰分析・相関分析なども解説しています。クラスター分析と組み合わせると、データの構造をより多角的に把握できます。
グループ分けの結果を使って「新しいデータがどのグループか」を判別したい場合は、線形判別分析(LDA)が適しています。既知のグループラベルを使って判別境界を学習する手法で、クラスター分析と組み合わせて使われることもあります。
複数の観測変数の背後にある共通因子を探りたい場合は、因子分析も検討してください。クラスター分析がデータをグループに分けるのに対し、因子分析は変数を少数の潜在因子に集約します。

