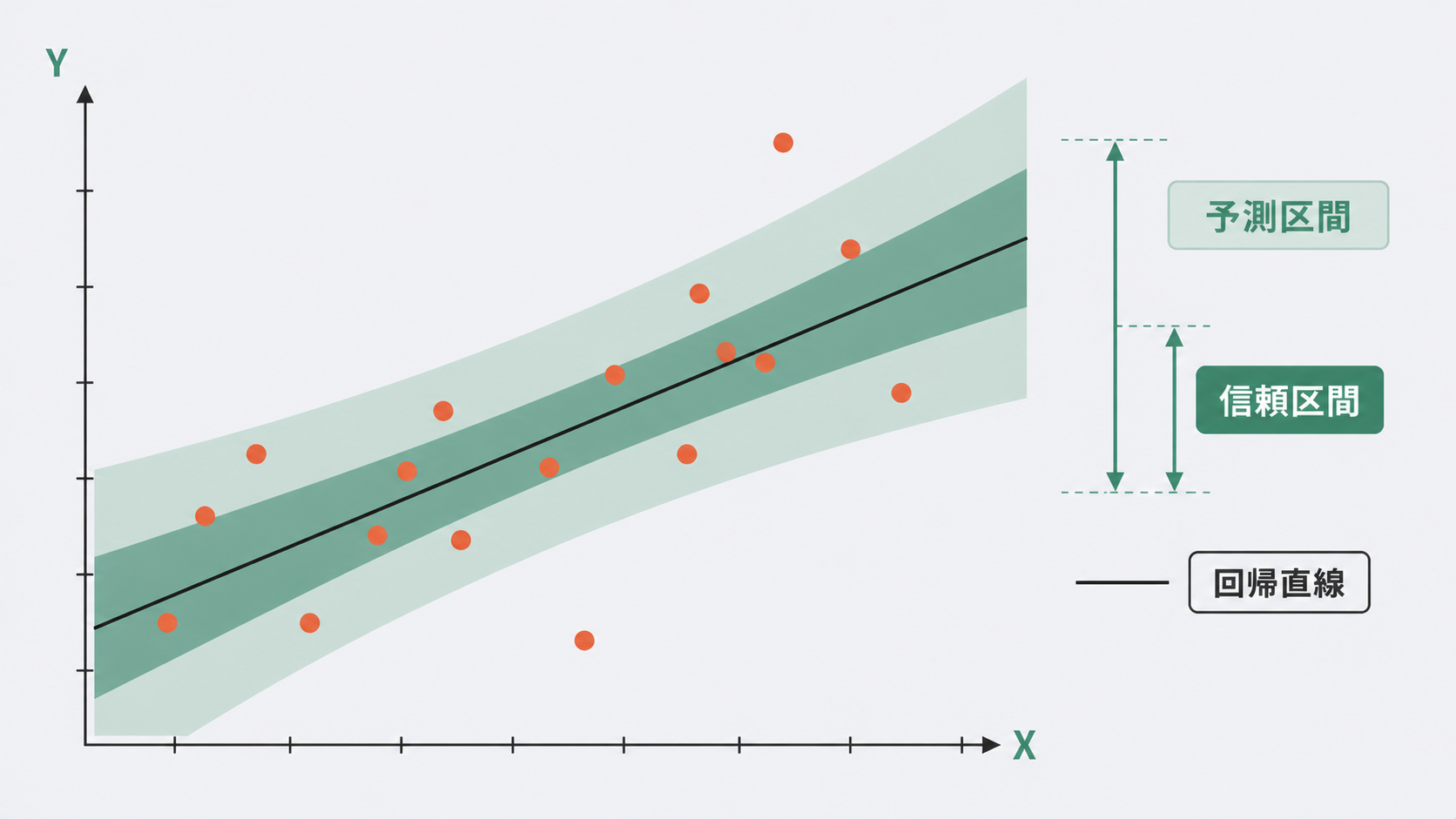
「この工程条件なら平均でどのくらいの強度になるか」と「次に作る1本の強度はどの範囲に収まるか」は、同じ回帰モデルを使っても答えが変わります。前者が信頼区間、後者が予測区間です。
この記事では、硬化温度と引張強度のデータ10点を例に、予測区間と信頼区間の公式・計算の違い・Excelでの実装手順を丁寧に解説します。「区間が2種類あって混乱する」という方が、読み終えるころには自信をもって使い分けられるようになることを目指しています。
予測区間と信頼区間:本質的な違い
回帰分析で特定のx値に対して区間推定をするとき、2つの異なる問いに答えることができます。
信頼区間(confidence interval for mean response)は、x = x* のときの平均応答 E[Y|x*] がどこにあるかを推定します。たとえば「硬化温度200℃で製造した製品の引張強度の母平均はどの範囲か」という問いです。
予測区間(prediction interval)は、x = x* で製造した次の1個の新しい観測値がどこに入るかを推定します。「次に硬化温度200℃で作る1本の強度はどの範囲に入るか」という問いです。
予測区間のほうが常に広くなります。信頼区間は「平均の不確かさ」だけを考慮しますが、予測区間はそれに加えて「個体ごとのばらつき(誤差)」も考慮する必要があるためです。実務上、合否判定や仕様外れのリスク評価には予測区間を使うべき場面がほとんどです。
例題データ:硬化温度と引張強度
熱処理工程の10バッチについて、硬化温度(℃)と引張強度(MPa)を記録したデータです。
| ロット | 硬化温度 x(℃) | 引張強度 y(MPa) |
|---|---|---|
| ロット1 | 150 | 312 |
| ロット2 | 160 | 326 |
| ロット3 | 170 | 335 |
| ロット4 | 180 | 354 |
| ロット5 | 190 | 361 |
| ロット6 | 200 | 382 |
| ロット7 | 210 | 388 |
| ロット8 | 220 | 407 |
| ロット9 | 230 | 416 |
| ロット10 | 240 | 429 |
STEP 1:単回帰モデルの推定
まず回帰係数 \(\hat{\beta}_1\)(傾き)と \(\hat{\beta}_0\)(切片)を最小二乗法で求めます。\[ \hat{\beta}_1 = \frac{S_{xy}}{S_{xx}}, \quad \hat{\beta}_0 = \bar{y} – \hat{\beta}_1 \bar{x} \]
各値を計算します。\[ \bar{x} = 195.0, \quad \bar{y} = 371.0 \] \[ S_{xx} = \sum(x_i – \bar{x})^2 = 8250.0, \quad S_{xy} = \sum(x_i – \bar{x})(y_i – \bar{y}) = 10830.0 \] \[ \hat{\beta}_1 = \frac{10830.0}{8250.0} = 1.3127 \approx 1.31 \] \[ \hat{\beta}_0 = 371.0 – 1.3127 \times 195.0 = 115.02 \]
推定式は次のとおりです。\[ \hat{y} = 115.02 + 1.31 \, x \]
決定係数 \(R^2 = 0.9952\)(99.5%)と、温度と強度の間に非常に強い線形関係が確認できます。
STEP 2:回帰の標準誤差 se を求める
予測区間の幅を決める重要な量が、回帰の標準誤差 \(s_e\)(残差の標準偏差)です。\[ s_e = \sqrt{\frac{SSE}{n-2}} \]
残差平方和 SSE を計算します。各ロットの予測値 \(\hat{y}_i = 115.02 + 1.31 x_i\) と実測値の差を二乗して合計します。
| ロット | x | y | ŷ | 残差 y−ŷ | 残差² |
|---|---|---|---|---|---|
| ロット1 | 150 | 312 | 311.93 | 0.07 | 0.01 |
| ロット2 | 160 | 326 | 325.05 | 0.95 | 0.89 |
| ロット3 | 170 | 335 | 338.18 | −3.18 | 10.12 |
| ロット4 | 180 | 354 | 351.31 | 2.69 | 7.24 |
| ロット5 | 190 | 361 | 364.44 | −3.44 | 11.81 |
| ロット6 | 200 | 382 | 377.56 | 4.44 | 19.68 |
| ロット7 | 210 | 388 | 390.69 | −2.69 | 7.24 |
| ロット8 | 220 | 407 | 403.82 | 3.18 | 10.12 |
| ロット9 | 230 | 416 | 416.95 | −0.95 | 0.89 |
| ロット10 | 240 | 429 | 430.07 | −1.07 | 1.15 |
| SSE | 69.16 | ||||
\[ s_e = \sqrt{\frac{69.16}{10 – 2}} = \sqrt{\frac{69.16}{8}} = \sqrt{8.645} = 2.940 \]
STEP 3:予測区間の計算
x* で新しい観測値を予測するときの 95% 予測区間の公式は次のとおりです。\[ \hat{y}(x^*) \pm t_{\alpha/2,\, n-2} \cdot s_e \cdot \sqrt{1 + \frac{1}{n} + \frac{(x^* – \bar{x})^2}{S_{xx}}} \]
x* = 200℃ で計算してみます。
まず予測値を求めます。\[ \hat{y}(200) = 115.02 + 1.3127 \times 200 = 377.56 \text{ MPa} \]
次に根号の中の factor を計算します。\[ \sqrt{1 + \frac{1}{10} + \frac{(200 – 195)^2}{8250}} = \sqrt{1 + 0.100 + 0.003} = \sqrt{1.103} = 1.050 \]
t値は自由度 \(df = n-2 = 8\)、両側 5% で \(t_{0.025,8} = 2.306\) です。\[ \text{誤差幅} = 2.306 \times 2.940 \times 1.050 = 7.12 \text{ MPa} \]
よって 95% 予測区間は次のとおりです。\[ 377.56 \pm 7.12 \quad \Rightarrow \quad (370.4 \text{ MPa},\ 384.7 \text{ MPa}) \]
STEP 4:信頼区間との数値比較
同じ x* = 200℃ で平均応答の 95% 信頼区間を求めます。公式から「1」を除いた形です。\[ \hat{y}(x^*) \pm t_{\alpha/2,\, n-2} \cdot s_e \cdot \sqrt{\frac{1}{n} + \frac{(x^* – \bar{x})^2}{S_{xx}}} \] \[ \sqrt{\frac{1}{10} + \frac{(200 – 195)^2}{8250}} = \sqrt{0.100 + 0.003} = \sqrt{0.103} = 0.321 \] \[ \text{誤差幅} = 2.306 \times 2.940 \times 0.321 = 2.18 \text{ MPa} \] \[ (375.4 \text{ MPa},\ 379.7 \text{ MPa}) \]
2つを並べると対比が明確になります。
| 区間の種類 | 中心値 ŷ | 下限 | 上限 | 幅 | 意味 |
|---|---|---|---|---|---|
| 95% 予測区間 | 377.56 | 370.4 | 384.7 | 14.3 MPa | 次の1本の強度がここに入る |
| 95% 信頼区間 | 377.56 | 375.4 | 379.7 | 4.3 MPa | 母平均の強度がここにある |
予測区間の幅(14.3 MPa)は信頼区間(4.3 MPa)の約3.3倍です。「個体差のばらつき」が加わるため、予測区間のほうが必然的に広くなります。
品質管理で「次のロットが規格 360〜400 MPa に入るか」を判断したいなら、信頼区間ではなく予測区間を見る必要があります。信頼区間だけを見て「大丈夫」と判断すると、実際の個体は区間外に出る可能性があります。
外挿時は区間が広がる
予測したい x* が測定範囲の外(外挿)になるほど、区間は広がります。x* = 250℃(データの最大値240℃を超える外挿)で計算すると、\[ \hat{y}(250) = 115.02 + 1.31 \times 250 = 443.2 \text{ MPa} \]
| x* | ŷ | 95% 予測区間 | 幅 |
|---|---|---|---|
| 200℃(範囲内) | 377.6 | 370.4 〜 384.7 | 14.3 MPa |
| 250℃(範囲外) | 443.2 | 435.0 〜 451.4 | 16.4 MPa |
x* = 250 は \(\bar{x} = 195\) からの距離が大きいので factor が増加し、区間が約15%広がっています。外挿した予測は不確実性が高まることが数値でも確認できます。外挿時は「回帰直線がそのまま成り立つかどうか」という前提自体も怪しくなるため、慎重に扱う必要があります。
回帰分析の前提確認については回帰分析の前提条件と残差分析も参照してください。
Excelでの計算手順
データをA列(ロット名)・B列(硬化温度 x)・C列(引張強度 y)に入力した状態を想定します。x* の値をF1セルに入力しておきます。
STEP 1:F2セルに予測値 ŷ を計算します。
=FORECAST.LINEAR(F1,C2:C11,B2:B11)
STEP 2:F3セルに回帰の標準誤差 se を計算します。
=STEYX(C2:C11,B2:B11)
STEP 3:F4セルに t 値を計算します(自由度 n−2 = 8、両側 5%)。
=T.INV.2T(0.05,COUNT(B2:B11)-2)
STEP 4:F5セルに予測区間の factor を計算します。
=SQRT(1+1/COUNT(B2:B11)+(F1-AVERAGE(B2:B11))^2/DEVSQ(B2:B11))
STEP 5:F6セルに予測区間の誤差幅を計算します。
=F3*F4*F5
STEP 6:F7・F8セルに下限・上限を出力します。
=F2-F6 ' 下限 =F2+F6 ' 上限
信頼区間を求めたい場合は STEP 4 の factor から「1」を除くだけです。
=SQRT(1/COUNT(B2:B11)+(F1-AVERAGE(B2:B11))^2/DEVSQ(B2:B11))
DEVSQ 関数が \(S_{xx} = \sum(x_i – \bar{x})^2\) を直接計算してくれるので、手動で計算する必要はありません。
95% 信頼区間の基本的な考え方は信頼区間の求め方の記事で詳しく解説しています。
重回帰への拡張
説明変数が複数ある重回帰分析でも、予測区間の考え方は同じです。公式は行列表記になりますが、「平均の区間(信頼区間)より個体の区間(予測区間)のほうが広い」という関係は変わりません。重回帰分析の結果の読み方と変数選択も合わせて参照してください。
まとめ
回帰分析の予測区間と信頼区間の要点をまとめます。
- 予測区間は「次の1個の観測値がどこに入るか」、信頼区間は「平均応答の真値がどこにあるか」
- 予測区間の公式: \(\hat{y} \pm t \cdot s_e \cdot \sqrt{1 + 1/n + (x^*-\bar{x})^2/S_{xx}}\)。信頼区間との違いは根号内の「1」だけ
- 予測区間は常に信頼区間より広い。今回の例(x*=200)で予測区間幅 14.3 MPa に対し信頼区間幅 4.3 MPa
- x* が \(\bar{x}\) から遠いほど(外挿するほど)区間が広がる
- 合否判定・仕様外れリスク評価には信頼区間ではなく予測区間を使う
- Excel では FORECAST.LINEAR / STEYX / DEVSQ / T.INV.2T を組み合わせて計算できる
回帰分析の基本的な計算手順は回帰分析のやり方と結果の見方で解説しています。そちらを理解したうえで予測区間の算出に進むと、一連の流れをよりスムーズに習得できます。