
この記事でわかること
- 乱塊法でブロックを使う理由(局所管理)と分散分析の手順(Excel対応)
- 完全無作為化法・二元配置との違いと使い分け
- 分割法の構造(1次因子・2次因子と2種類の誤差)
新しい触媒3種類の収率を比べたい。ところが原料は4つのロットから取っており、ロットが違うと収率の水準そのものがずれることが分かっています。全部の実験をバラバラの順で行うと、触媒の差なのかロットの差なのか区別がつきません。こうした「邪魔な変動源」がはっきりしているときに使うのが乱塊法です。
乱塊法はフィッシャーの3原則の1つ「局所管理」を実現する配置法です。さらに、因子の割り付けに物理的な制約があるときに使う分割法まで含めて、この記事では分散分析表の作り方と一緒に解説します。どちらもQC検定2級の実験計画法でよく問われるテーマです。
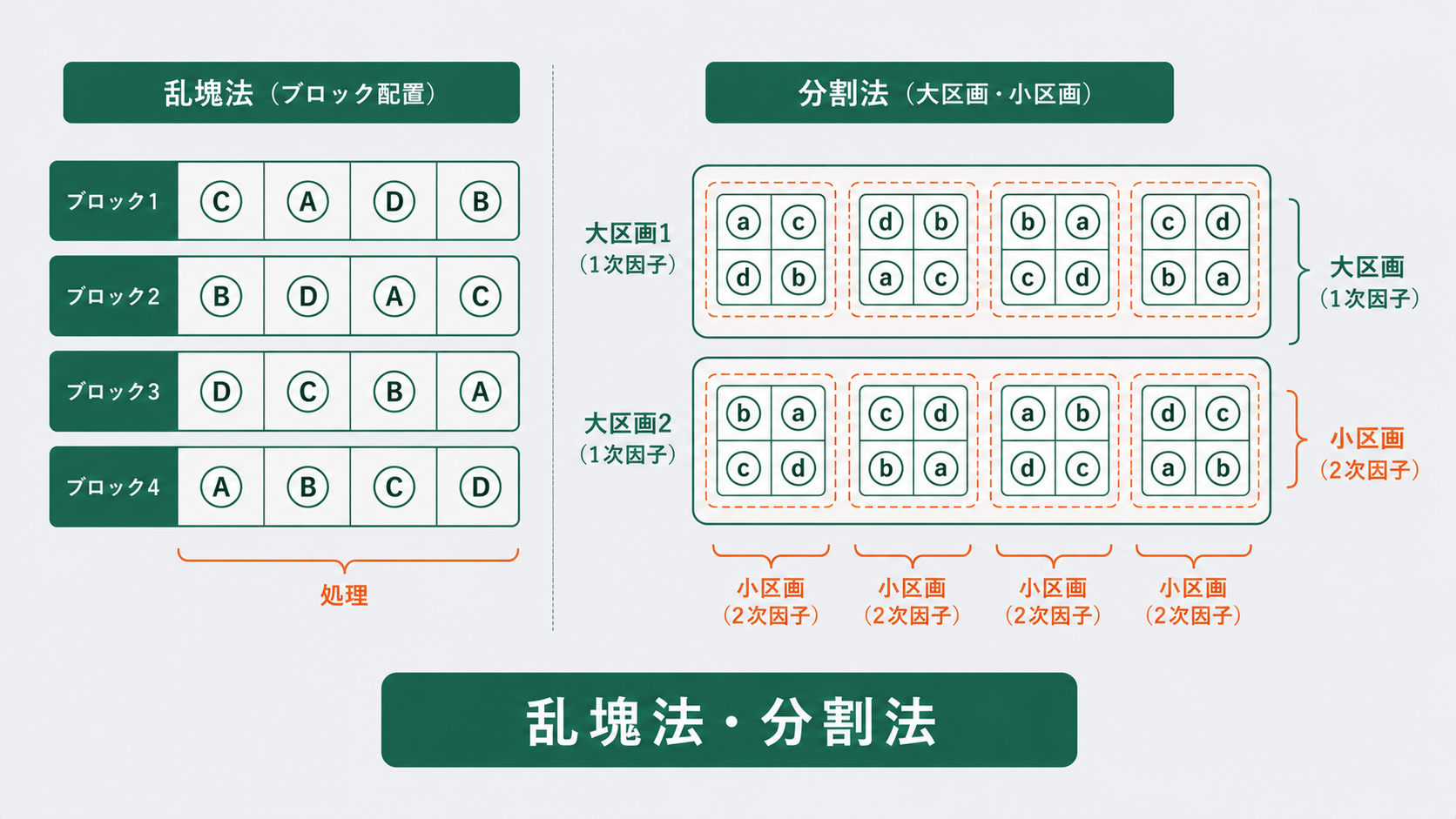
乱塊法・分割法を使う場面
2つの手法は、どちらも「実験全体を完全にランダムにはできない事情」があるときに使います。事情の種類で使い分けます。
- 乱塊法:調べたい因子のほかに、収率や特性に影響する既知の変動源(ロット・日・装置・作業者など)があるとき。その変動源をブロックにまとめ、各ブロック内で処理をランダムに割り付ける
- 分割法:2つの因子のうち、一方は水準を頻繁に変えられない(炉の温度設定など段取り替えが大変)とき。変えにくい因子を大きな区画に、変えやすい因子をその中の小区画に割り付ける
逆に、影響しそうな外乱が特に見当たらず、すべての実験を自由な順序でランダムに行えるなら、ブロックを設けない一元配置分散分析(完全無作為化法)で十分です。まず外乱の有無を見極めることが出発点です。
完全無作為化法との違い(局所管理)
完全無作為化法は、すべての実験を完全にランダムな順序で行う方法です。外乱が小さければ問題ありませんが、ロット差のような大きな変動源があると、その変動がまるごと誤差に含まれてしまいます。誤差が大きくなると、本当に知りたい因子の効果が埋もれて検出しにくくなります。
そこで、似た条件のまとまり(ブロック)を作り、その中だけでランダム化するのが局所管理です。乱塊法ではブロック間の変動を分散分析で分離し、誤差から取り除きます。結果として誤差が小さくなり、因子の検出力が上がります。これがブロックを設ける最大のねらいです。
局所管理はフィッシャーの3原則(反復・無作為化・局所管理)の1つです。3原則の全体像は実験計画法とはで解説しています。
乱塊法の分散分析(例題)
触媒A・B・Cの3水準を比べます。原料ロットが4つあり、ロットをブロックとします。各ロットの中で3つの触媒をランダムな順で試し、収率(%)を測定しました。データは次のとおりです。
| 触媒\ロット | ロット1 | ロット2 | ロット3 | ロット4 | 処理計 |
|---|---|---|---|---|---|
| A | 81 | 82 | 80 | 81 | 324 |
| B | 84 | 89 | 83 | 88 | 344 |
| C | 78 | 81 | 77 | 80 | 316 |
| ブロック計 | 243 | 252 | 240 | 249 | 984 |
計算の構造は「繰り返しのない二元配置」と同じです。処理(触媒)とブロック(ロット)の2方向で平方和を分解します。総データ数 N=12、総計 G=984 から、修正項 CF を求めます。
CF = G² / N = 984² / 12 = 80688
全体の平方和は、各データの2乗和から CF を引いて求めます。各データの2乗和は Σx² = 80830 です。Excelでは平方和の計算に DEVSQ 関数が使えます(=DEVSQ(範囲) で「偏差平方和」が一度に出ます)。
- 総平方和 ST = Σx² − CF = 80830 − 80688 = 142
- 処理平方和 SA = (324² + 344² + 316²)/4 − CF = 80792 − 80688 = 104
- ブロック平方和 SB = (243² + 252² + 240² + 249²)/3 − CF = 80718 − 80688 = 30
- 誤差平方和 SE = ST − SA − SB = 142 − 104 − 30 = 8
処理は触媒の合計(4データ分)を2乗して4で割り、ブロックはロットの合計(3データ分)を2乗して3で割る点に注意します。自由度は、処理 = 水準数−1 = 2、ブロック = ブロック数−1 = 3、誤差 = 2×3 = 6、全体 = N−1 = 11 です。これらを分散分析表にまとめます。
| 要因 | 平方和 S | 自由度 φ | 平均平方 V | F値 |
|---|---|---|---|---|
| 処理(触媒) | 104 | 2 | 52.0 | 39.0 |
| ブロック(ロット) | 30 | 3 | 10.0 | 7.5 |
| 誤差 | 8 | 6 | 1.333 | — |
| 合計 | 142 | 11 | — | — |
平均平方は平方和を自由度で割った値で、F値は各要因の平均平方を誤差の平均平方で割って求めます。
- 処理の F = 52.0 / 1.333 = 39.0
- ブロックの F = 10.0 / 1.333 = 7.5
有意水準5%のF分布の境界値は、処理が F(2, 6) = 5.14、ブロックが F(3, 6) = 4.76 です。ExcelではF.INV.RT関数で求めます(=F.INV.RT(0.05, 2, 6))。処理の F=39.0 は5.14を大きく超えるので、触媒の違いは収率に有意な差があるといえます。
ブロックの F=7.5 も4.76を超えており、ロット間にも有意な差があります。これは「ロットをブロックにして正解だった」という意味です。もしブロックを無視して完全無作為化していたら、この30の変動が誤差に混ざり、触媒の検出が難しくなっていました。Excelでは「分析ツール」の「分散分析:繰り返しのない二元配置」を使えば、同じ表が自動で出力されます。
分散分析を行う前提(正規性・等分散・独立性)の確認方法は分散分析の前提条件を、二元配置の基本手順は二元配置分散分析を例題で解説をご覧ください。
分割法の構造(2種類の誤差)
分割法は、2つの因子の「変えやすさ」が違うときに使います。たとえば熱処理の炉温度A(段取り替えが大変で頻繁に変えられない)と、その中で処理する材料B(同じ炉に複数並べられる)を同時に調べる場合です。
このとき、変えにくい因子Aを大きな区画(1次因子・主区画)に割り付け、変えやすい因子Bをその中の小区画(2次因子・副区画)に割り付けます。Aを「ある温度に設定した1回の炉立ち上げ」がひとまとまりになるため、完全にはランダム化できません。ここが完全無作為化や乱塊法と決定的に違う点です。
割り付けに段階があるため、誤差も2種類に分かれます。これが分割法の最大の特徴です。
- 1次誤差:主区画の間のばらつき。変えにくい因子A(1次因子)の検定に使う
- 2次誤差:小区画の間のばらつき。変えやすい因子B(2次因子)と交互作用A×Bの検定に使う
反復(ブロック)R、1次因子A、2次因子Bを組んだ分割法の分散分析表は、要因と自由度が次のように並びます(A が a 水準、B が b 水準、反復が r のとき)。
| 要因 | 自由度 φ | 検定に使う誤差 |
|---|---|---|
| 反復 R | r−1 | — |
| 1次因子 A | a−1 | 1次誤差 |
| 1次誤差(R×A) | (r−1)(a−1) | — |
| 2次因子 B | b−1 | 2次誤差 |
| 交互作用 A×B | (a−1)(b−1) | 2次誤差 |
| 2次誤差 | a(r−1)(b−1) | — |
ポイントは、因子AのF値は1次誤差で、因子BとA×BのF値は2次誤差で計算することです。すべてを1つの誤差で割ってはいけません。一般に1次誤差は2次誤差より大きくなりやすく、変えにくい因子Aは精度が落ちる(検出しにくい)傾向があります。だからこそ、本当に知りたい因子は変えやすい2次因子に置くのがセオリーです。
まとめ
乱塊法と分割法のポイントを整理します。
- 乱塊法は既知の外乱をブロックにまとめて誤差から分離する(局所管理)。検出力が上がる
- 乱塊法の計算は繰り返しのない二元配置と同じ。ブロックも1要因として平方和を分解する
- 例題では触媒 F=39.0、ロット F=7.5 でともに有意。ブロック化が有効だったと確認できた
- 分割法は因子の割り付けに制約があるときに使い、誤差が1次・2次の2種類に分かれる
- 分割法では1次因子は1次誤差で、2次因子・交互作用は2次誤差で検定する
使い分けの目安はシンプルです。外乱を消したいなら乱塊法、変えにくい因子があるなら分割法、どちらもなければ完全無作為化(一元配置)。実験の制約に合わせて配置を選びます。QC検定2級の実験計画法分野の学習順はQC検定2級 手法編の攻略ロードマップで分野別に整理しています。基本となる分散分析は二元配置分散分析もあわせてご確認ください。

