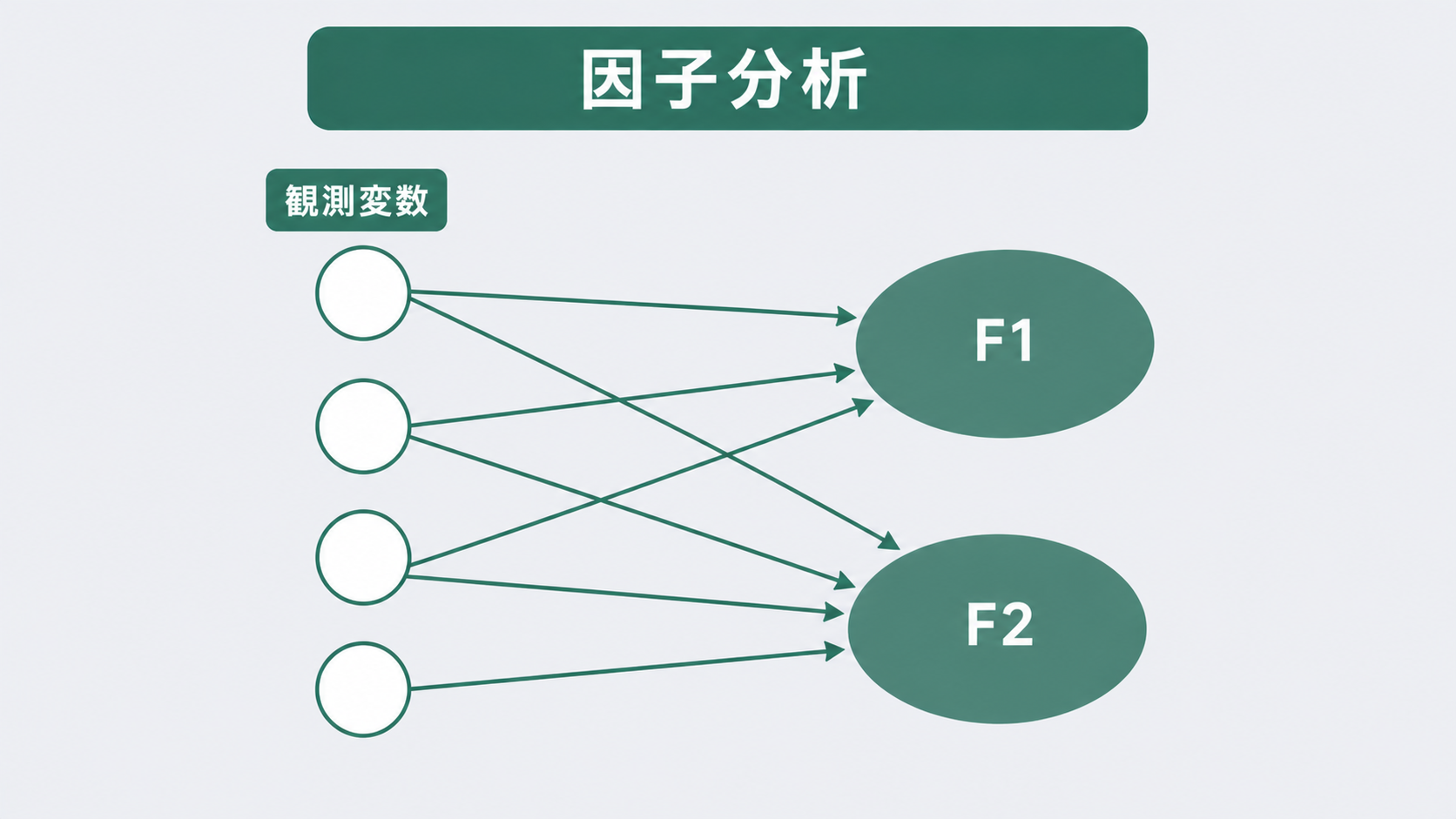
複数の検査項目を測定していると、「これとこれは似た動きをするな」と感じることがあります。引張強度と硬さが一緒に上下する、寸法精度と外観評価が連動するといった傾向です。
この記事では、そういった共通の動きを「潜在因子」として取り出す手法、因子分析(EFA:Exploratory Factor Analysis)を解説します。相関行列から固有値を求め、バリマックス回転で因子を解釈する手順を製造業の例題でたどります。
因子分析とは:PCaとの違いから入る
主成分分析(PCA)と因子分析は、どちらも多変量データを少ない軸で要約する手法です。ただし目的が違います。
PCAは「データの分散をできるだけ説明する新しい軸を作る」数学的な変換です。因子分析は「観測変数の背後にある、直接測れない共通要因(潜在因子)を推定する」統計モデルです。
因子分析のモデルは次の式で表されます。\[ x_j = a_{j1} F_1 + a_{j2} F_2 + \cdots + a_{jk} F_k + e_j \]
\( x_j \) が観測変数、\( F_k \) が潜在因子、\( a_{jk} \) が因子負荷量(factor loading)、\( e_j \) が固有因子(誤差)です。因子負荷量が大きいほど、その変数はその因子と強く結びついています。
使いどころの目安はこうです。
例題:プレス部品の検査データ(4変数・12ロット)
プレス部品の製造ラインで12ロット分の品質検査を実施しました。測定項目は次の4つです。
- \( x_1 \):表面硬さ(HRC)
- \( x_2 \):引張強度(kgf/mm²)
- \( x_3 \):寸法精度スコア(10点満点、高いほど良い)
- \( x_4 \):外観評価スコア(100点満点、高いほど良い)
| ロット | \( x_1 \) 硬さ(HRC) | \( x_2 \) 引張強度(kgf/mm²) | \( x_3 \) 精度スコア | \( x_4 \) 外観スコア |
|---|---|---|---|---|
| 1 | 51.3 | 142 | 9.0 | 70 |
| 2 | 46.9 | 133 | 4.9 | 69 |
| 3 | 47.4 | 126 | 10.2 | 86 |
| 4 | 44.8 | 110 | 4.8 | 66 |
| 5 | 41.8 | 111 | 10.4 | 82 |
| 6 | 41.3 | 104 | 7.0 | 70 |
| 7 | 45.6 | 128 | 4.9 | 64 |
| 8 | 46.2 | 125 | 10.2 | 73 |
| 9 | 45.0 | 122 | 8.1 | 72 |
| 10 | 47.2 | 129 | 7.5 | 62 |
| 11 | 41.4 | 104 | 6.9 | 76 |
| 12 | 46.3 | 140 | 6.7 | 76 |
直感的に「\( x_1 \) と \( x_2 \) は似た動きをしそう」「\( x_3 \) と \( x_4 \) も連動しているかも」という仮説を持ちながら分析を進めます。
Step 1:相関行列を求める
まず4変数の相関行列を計算します。Excelなら「データ分析」→「相関」で一括出力できます(CORREL関数でもOKです)。
| \( x_1 \) | \( x_2 \) | \( x_3 \) | \( x_4 \) | |
|---|---|---|---|---|
| \( x_1 \) 硬さ | 1.000 | 0.887 | 0.100 | −0.195 |
| \( x_2 \) 引張強度 | 0.887 | 1.000 | 0.034 | −0.135 |
| \( x_3 \) 精度スコア | 0.100 | 0.034 | 1.000 | 0.661 |
| \( x_4 \) 外観スコア | −0.195 | −0.135 | 0.661 | 1.000 |
\( x_1 \) と \( x_2 \) は r = 0.887 と強く相関しています。\( x_3 \) と \( x_4 \) も r = 0.661 と連動しています。一方で、「硬さ・強度」グループと「精度・外観」グループの間の相関は低く(最大でも r = 0.195)、2つの独立したグループが存在することが読み取れます。
Step 2:固有値を求めて因子数を決める
相関行列の固有値分解を行います。固有値は「その因子がデータ全体の分散をどれだけ説明するか」を示します。
| 因子 | 固有値 \( \lambda \) | 寄与率 | 累積寄与率 |
|---|---|---|---|
| 1 | 1.95 | 48.8% | 48.8% |
| 2 | 1.63 | 40.7% | 89.6% |
| 3 | 0.32 | 8.1% | 97.7% |
| 4 | 0.09 | 2.3% | 100.0% |
因子数の決め方として最もよく使われるのがカイザー基準(固有値 > 1)です。固有値が1を超える因子は「標準化した1変数分以上の情報を持つ」とみなせます。今回は固有値 > 1 の因子が2つあるので、2因子解を採用します。
累積寄与率は 89.6% で、2因子で全体の約9割の変動を説明できています。
Step 3:初期因子負荷量を求める
主成分法を使って、固有ベクトルと固有値から初期の因子負荷量を計算します。計算式は\[ a_{jk} = e_{jk} \sqrt{\lambda_k} \]
\( e_{jk} \) は第 \( k \) 固有ベクトルの \( j \) 番目の成分です。
| 変数 | F1 | F2 | 共通性 \( h^2 \) |
|---|---|---|---|
| \( x_1 \) 硬さ | 0.933 | −0.283 | 0.950 |
| \( x_2 \) 引張強度 | 0.924 | −0.276 | 0.931 |
| \( x_3 \) 精度スコア | −0.177 | 0.907 | 0.854 |
| \( x_4 \) 外観スコア | −0.445 | 0.806 | 0.848 |
共通性 \( h^2 \) は各変数が因子によって説明される割合です。\( h^2 = a_{j1}^2 + a_{j2}^2 \) で計算します。今回はすべての変数で 0.85 以上と高く、2因子で十分に説明できています。
この段階でも「F1はx1・x2と、F2はx3・x4と結びついている」傾向は見えます。ただし、回転前は因子の解釈がやや不明瞭な場合があります。
Step 4:バリマックス回転で因子を明確にする
因子解釈を簡単にするため、バリマックス回転(直交回転)を適用します。各変数の負荷量を「0に近いか1に近いか」の二極化を目指すことで、因子の意味が読み取りやすくなります。
| 変数 | F1(回転後) | F2(回転後) | 共通性 \( h^2 \) |
|---|---|---|---|
| \( x_1 \) 硬さ | 0.975 | −0.021 | 0.950 |
| \( x_2 \) 引張強度 | 0.964 | −0.026 | 0.931 |
| \( x_3 \) 精度スコア | 0.114 | 0.917 | 0.854 |
| \( x_4 \) 外観スコア | −0.172 | 0.905 | 0.848 |
回転後は構造が非常にシンプルになりました。
- F1:\( x_1 \) と \( x_2 \) が高負荷(0.96〜0.98)、\( x_3 \)・\( x_4 \) は低負荷 → 機械的強度因子と命名
- F2:\( x_3 \) と \( x_4 \) が高負荷(0.90〜0.92)、\( x_1 \)・\( x_2 \) は低負荷 → 加工品質因子と命名
因子寄与は F1 = 1.92(総寄与率の 48.1%)、F2 = 1.66(41.5%)で、2因子合計で変動の 89.6% を説明します。
Step 5:結果の読み方と実務への応用
因子負荷量の解釈基準
一般的な目安として、|負荷量| ≥ 0.5 であればその因子への「強い結びつき」とみなします。今回の結果では、F1と F2 それぞれに明確に2変数が属しており、解釈が容易です。
因子スコアの活用
各ロットの「機械的強度因子スコア」と「加工品質因子スコア」を計算すると、ロットごとの特性を2次元で可視化できます。たとえば「F1は高いがF2が低い → 強度は出ているが仕上げが不安定」といった判断が直感的にできます。
因子スコアの簡易計算(バートレット法の近似):\[ \hat{F}_k \approx \sum_j \frac{a_{jk}}{h_j^2} \cdot z_j \]
\( z_j \) は標準化した観測値(平均0・分散1)です。
分析後のアクション例
- F1(機械的強度)に問題があるロット → 材料組成・熱処理条件を確認
- F2(加工品質)にばらつきが多いロット → 工具摩耗・加工条件を確認
- F1とF2の両方を管理指標として設定 → 多数の検査項目を2つの指標に集約できる
Excelでの実施手順
Step 1:相関行列を計算する
- 「データ」→「データ分析」→「相関」を選択
- 4変数のデータ範囲を入力範囲に指定
- 「先頭行をラベルとして使用」にチェックして実行
Step 2:固有値を求める
Excelには固有値を直接求める関数がありません。実務では次のいずれかを使います。
- 冪乗法(手計算寄り):相関行列に任意ベクトルを繰り返し掛けて収束させる方法。Excelの MMULT 関数で実装できます
- Pythonを使う:
numpy.linalg.eigh(R)で即座に求められます。主成分分析の記事でも同じ関数を使っています
Step 3:因子負荷量を計算する
固有値 \( \lambda_k \) と固有ベクトル \( \boldsymbol{e}_k \) が得られたら:\[ \text{因子負荷量(第}j\text{変数・第}k\text{因子)} = e_{jk} \times \sqrt{\lambda_k} \]
Excelなら MMULT を使って行列計算できます。
Step 4:バリマックス回転
回転のアルゴリズムは繰り返し計算を伴うため、Excelのマクロ(VBA)またはPythonが現実的です。Python の sklearn.decomposition.FactorAnalysis や factor_analyzer ライブラリを使うと、バリマックス回転まで一括で実行できます。
手軽に試すならPythonを
from factor_analyzer import FactorAnalyzer
import pandas as pd
df = pd.DataFrame(data, columns=['硬さ','引張強度','精度スコア','外観スコア'])
fa = FactorAnalyzer(n_factors=2, rotation='varimax')
fa.fit(df)
print(fa.loadings_)
Pythonを使った多変量解析の詳細は主成分分析の記事も参考にしてください。
因子分析の注意点
サンプルサイズ
変数の5〜10倍以上のサンプルが望ましいとされています。今回の例は4変数・12サンプルで変数の3倍しかありません。実務では最低でも変数数の5倍(今回なら20サンプル以上)を用意することをおすすめします。
因子数の決め方は複数ある
カイザー基準(固有値>1)のほかに、スクリープロット(固有値の折れ線グラフが急に平坦になる箇所)を見る方法もあります。両方を確認してから因子数を決めると安心です。
回転の種類
バリマックス回転は「因子間が無相関」という直交回転です。因子間に相関がありそうな場合は、プロマックス回転(斜交回転)の方が実態に合うこともあります。
まとめ
因子分析の計算手順をまとめます。
- 相関行列を求める(Excel:データ分析→相関)
- 固有値分解で因子数を決める(カイザー基準:固有値>1)
- 因子負荷量を計算する(固有ベクトル × √固有値)
- バリマックス回転で構造を単純化する
- 因子に名前をつけて解釈する(|負荷量| ≥ 0.5 が目安)
今回の例では、4つの品質指標の背後に「機械的強度因子(F1)」と「加工品質因子(F2)」が存在することが確認できました。多数の測定項目を少数の意味ある軸に集約できるのが因子分析の強みです。
多変量解析の全体像についてはクラスター分析・主成分分析の記事とあわせて参照してください。これら3手法は目的に応じて使い分けるものです。