
中心極限定理とは|標本平均が正規分布に近づく理由
この記事でわかること
- 中心極限定理が「何を保証してくれる定理か」を直感的に理解できる
- 標準誤差 σ/√n の意味と、標本平均のばらつきがnで縮む理由
- Excelでサイコロの平均をシミュレーションして定理を体感する手順
- 大数の法則との違い・よくある誤解
製造ラインから部品を36個だけ抜き取り、平均重量を測ったとします。「このたった36個の平均から、ライン全体の重さをどこまで信用していいのか?」——抜き取り検査や工程管理をしていると、必ずこの疑問にぶつかります。
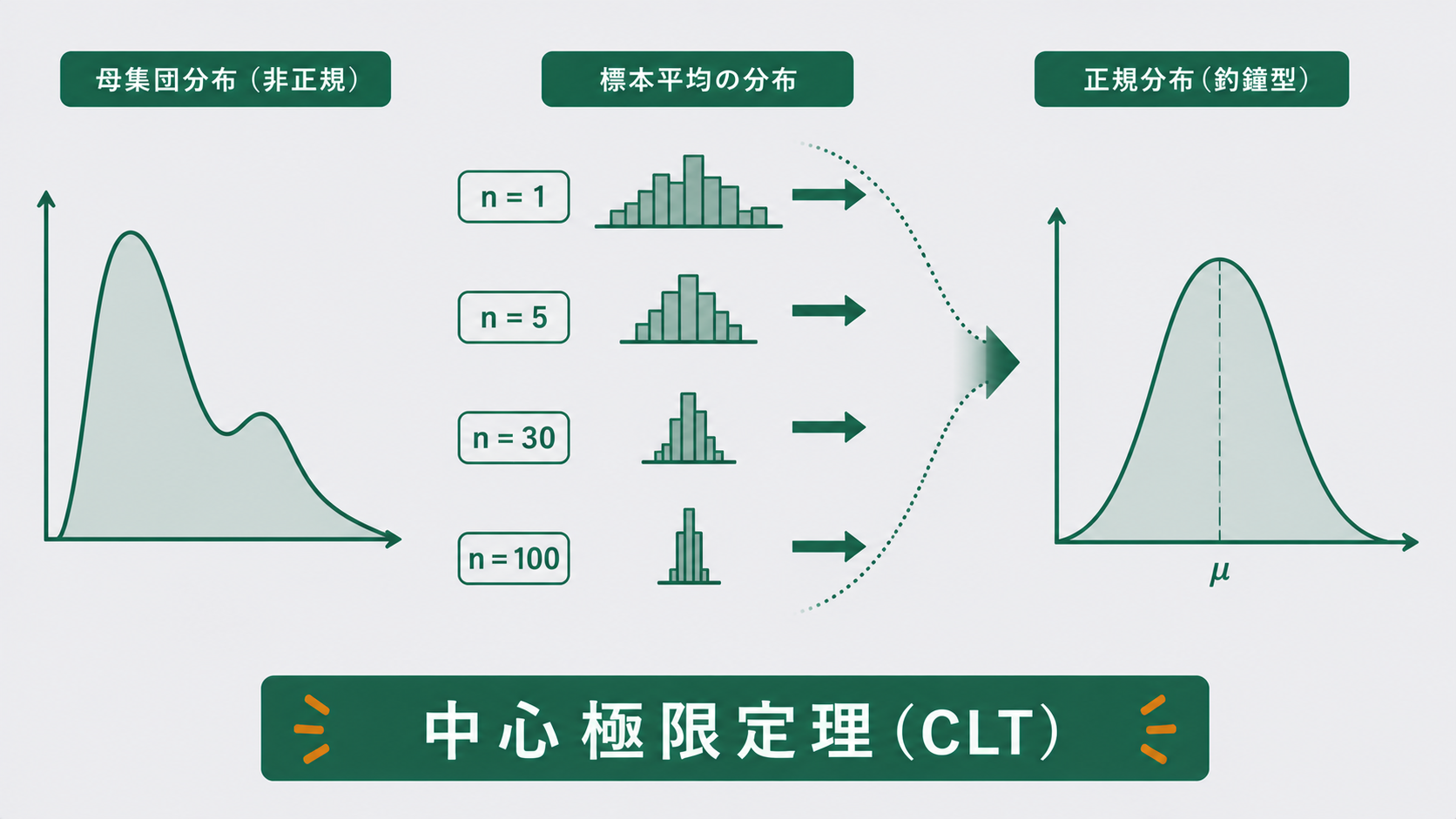
不思議なのは、元になる部品の重量分布が左右非対称だろうと、デコボコしていようと、抜き取った標本の「平均値」だけはきれいな正規分布に従うという点です。この一見すると都合がよすぎる現象を保証してくれるのが、統計学でもっとも重要な定理のひとつ、中心極限定理です。
この記事では、中心極限定理が実務で何を意味するのかを、Excelのシミュレーションと製造業の数値例で具体的に解説します。
中心極限定理が効いてくる場面
中心極限定理は、表に出ないところで統計手法の土台を支えています。次のような場面では、知らないうちにこの定理の恩恵を受けています。
- 抜き取り検査で平均を推定するとき:少数の標本平均から母平均を区間推定する。信頼区間が正規分布で計算できるのは、標本平均が正規分布に近づくからです。
- 2群の平均差を検定するとき:t検定は標本平均の分布が正規であることを前提にしています。
- 工程の平均をX̄管理図で監視するとき:管理限界を平均±3σの正規分布で引けるのも、サブグループ平均が正規分布に近づくためです。
逆に注意したい場面もあります。
(△)中心極限定理が保証するのは「標本平均の分布」であって、個々のデータの分布ではありません。製品1個1個の重量が正規分布になるわけではない点に注意してください。
(△)標本サイズが極端に小さい(n=2〜3程度)うえ、母集団の歪みが非常に強い場合は、平均でも正規分布への近づきが甘くなります。
中心極限定理とは(3つのポイント)
中心極限定理(Central Limit Theorem, CLT)は、ざっくり言うと次のように説明できます。
母集団がどんな分布であっても、そこから大きさ n の標本を取り出して平均を計算する操作を繰り返すと、その標本平均 \( \bar{x} \) の分布は、n が大きくなるにつれて正規分布に近づく。
ポイントは3つです。
① 母集団の形を問わない
母集団が一様分布でも、指数分布のように右に裾を引いた形でも、二峰性でも構いません。元の形がなんであれ、平均をとると正規分布に化けます。ここが「魔法のようだ」と言われるゆえんです。
② 平均の中心は母平均と同じ
標本平均 \( \bar{x} \) の期待値は、母平均 \( \mu \) と一致します。つまり標本平均は、平均的には母平均を当てにいく推定量です。
\[ E[\bar{x}] = \mu \]
③ ばらつきは n で縮む
標本平均の標準偏差は、母標準偏差 \( \sigma \) を \( \sqrt{n} \) で割った値です。これを標準誤差(standard error, SE)と呼びます。
\[ SE = \frac{\sigma}{\sqrt{n}} \]
サンプルを増やすほど平均のばらつきは小さくなり、推定が安定します。ただし分母が \( \sqrt{n} \) なので、精度を2倍にするにはサンプルを4倍にする必要があります。この「効きの鈍さ」はサンプルサイズの決め方で重要になる感覚です。
標準偏差と標準誤差は違う(混同しやすい点)
実務でいちばん混同されるのが、標準偏差(SD)と標準誤差(SE)です。両者はまったく別物なので、ここで整理しておきます。
| 観点 | 標準偏差 SD | 標準誤差 SE |
|---|---|---|
| 測っているもの | データ1個1個のばらつき | 標本平均のばらつき |
| 式 | \( \sigma \)(または s) | \( \sigma / \sqrt{n} \) |
| nを増やすと | ほぼ変わらない | 小さくなる |
| 使う場面 | 製品のばらつき・規格との比較 | 平均の信頼区間・検定 |
標準偏差は「製品がどれだけバラつくか」、標準誤差は「平均値の推定がどれだけ揺れるか」を表します。データを増やしても製品のばらつき(SD)は減りませんが、平均の推定精度(SE)は上がる——この区別が決定的に重要です。
Excelでサイコロの平均をシミュレーションする
中心極限定理は、手を動かすといちばん腑に落ちます。題材はサイコロです。1個のサイコロの出目は1〜6が等確率の「一様分布」で、釣鐘型とはほど遠い形です。
サイコロ1個の理論値を確認しておきます。出目の母平均は
\[ \mu = \frac{1+2+3+4+5+6}{6} = 3.5 \]
母分散は \( E[X^2] – \mu^2 \) で求まります。\( E[X^2] = (1+4+9+16+25+36)/6 = 91/6 \approx 15.1667 \) なので、
\[ \sigma^2 = 15.1667 – 3.5^2 = 2.9167, \quad \sigma \approx 1.7078 \]
手順
- セルに
=RANDBETWEEN(1,6)を入力し、横に n 個ぶんコピーしてサイコロ n 個を1セットにする。 - その行の右端で
=AVERAGE(A2:E2)(n=5なら5セル)として、1セットの平均を出す。 - この行を1000行ぶんコピーすると、「サイコロn個の平均」が1000個できる。
- 1000個の平均値をヒストグラム化する(Excelでヒストグラムを作る手順を参照)。
n を 1 → 5 → 30 と増やしてヒストグラムを見比べると、n=1ではデコボコの平らな形だったものが、nが大きくなるほど中央が盛り上がった釣鐘型に変わっていきます。これが中心極限定理を「見た」瞬間です。
理論上、サイコロn個の平均の標準誤差は \( SE = \sqrt{2.9167 / n} \) で予測できます。シミュレーションのばらつき(標本平均たちの標準偏差を =STDEV.P で測る)が、この理論値に近づくのも確認してみてください。
| サイコロの個数 n | 平均の標準誤差 SE(理論値) |
|---|---|
| 1 | 1.708 |
| 2 | 1.208 |
| 5 | 0.764 |
| 10 | 0.540 |
| 30 | 0.312 |
nが増えるほど、平均が3.5付近にギュッと集まっていくのが数値でもわかります。
製造業の数値例:抜き取り平均の確率を計算する
具体的な例で計算してみましょう。ある部品の重量が、母平均 \( \mu = 50 \)g、母標準偏差 \( \sigma = 6 \)g の分布に従っているとします(元の分布の形は問いません)。ここから36個を抜き取り、その平均重量を考えます。
中心極限定理より、標本平均の分布は次の正規分布に近づきます。
\[ \bar{x} \sim N\left(50,\ \left(\frac{6}{\sqrt{36}}\right)^2\right) = N(50,\ 1.0^2) \]
標準誤差は \( SE = 6/\sqrt{36} = 1.0 \)g です。個々の部品は標準偏差6gでバラつくのに、36個の平均は標準偏差1.0gにまで安定する点に注目してください。
例題:平均が51gを超える確率は?
標本平均が51gを超える確率を求めます。標準化すると、
\[ Z = \frac{51 – 50}{1.0} = 1.0 \]
標準正規分布で Z が 1.0 を超える確率なので、ExcelではNORM.S.DIST関数を使います。
=1-NORM.S.DIST(1, TRUE)
→ 0.1587つまり「36個の平均が51gを超える」確率は約15.9%です。1個あたりの分布を直接使うよりずっと小さな確率になるのは、平均化でばらつきが縮んでいるためです。
例題:平均が48〜52gに収まる確率は?
同じ設定で、標本平均が48g〜52gに収まる確率を求めます。両端を標準化すると \( Z = \pm 2.0 \) です。
=NORM.S.DIST(2, TRUE) - NORM.S.DIST(-2, TRUE)
→ 0.9545約95.5%の確率で、36個の平均は48〜52gに収まります。±2SE(=±2.0g)の幅に約95%が入るという、信頼区間の感覚そのものです。
大数の法則との違い(よくある誤解)
中心極限定理は「大数の法則」と混同されがちですが、語っている内容が異なります。
| 観点 | 大数の法則 | 中心極限定理 |
|---|---|---|
| 主張 | nを増やすと標本平均が母平均に近づく | 標本平均の分布の形が正規分布に近づく |
| 関心 | 平均が「どこに」収束するか | 平均が「どんな形で」ばらつくか |
| 使い道 | 推定の一致性 | 区間推定・検定の理論的根拠 |
大数の法則は「数をこなせば平均は正しい値に近づく」という収束先の話、中心極限定理は「その平均のブレが正規分布の形になる」というばらつきの形の話です。両者は補い合う関係にあります。
もうひとつのよくある誤解が「中心極限定理があるから、どんなデータでも正規分布として扱ってよい」というものです。正規分布に近づくのは平均であって、生データそのものではありません。例えば工程能力指数のように個々のデータの正規性が前提になる手法では、中心極限定理は言い訳になりません。正規性の検定などで別途確認する必要があります。
QC検定での問われ方とミニ例題
QC検定では、中心極限定理は2級・3級の「データの取り方・まとめ方」や統計的方法の基礎で問われます。とくに標準誤差の式 \( \sigma/\sqrt{n} \) を使った計算が頻出です。
QC検定でよく問われるポイントは次の3つです。
- 母集団の分布によらず標本平均が正規分布に近づく、という定理の意味
- 標本平均の標準偏差(標準誤差)が \( \sigma/\sqrt{n} \) であること
- nを4倍にすると標準誤差が半分になる、という \( \sqrt{n} \) の効き方
ミニ例題:母標準偏差が \( \sigma = 8 \) の工程から、n = 16 のサンプルを取って平均を求める。標本平均の標準誤差はいくらか。
解答:\( SE = 8 / \sqrt{16} = 8 / 4 = 2 \)。標準誤差は2です。もしSEを1(半分)にしたければ、nを4倍の64にする必要があります(\( 8/\sqrt{64} = 1 \))。\( \sqrt{n} \) で効くという感覚を、この計算で押さえておきましょう。
よくある質問(FAQ)
Q. 標本サイズnはいくつ以上あれば正規分布とみなせますか?
A. 目安としてn≧30がよく使われます。ただしこれは経験則で、母集団の歪みが小さければn=10程度でも十分近づき、歪みが極端に強ければ30でも足りないことがあります。あくまで母集団の形しだいです。
Q. 母標準偏差σがわからない場合はどうすればよいですか?
A. 標本から計算した標準偏差sで代用します。ただしその場合、標本平均の分布は正規分布ではなくt分布に従います。これがt検定でt分布を使う理由です。
Q. 中心極限定理と大数の法則は何が違いますか?
A. 大数の法則は標本平均が母平均に近づく「収束先」の話、中心極限定理は標本平均のばらつきが正規分布の「形」になる話です。関心の対象が異なります。
Q. 個々のデータも正規分布になるのですか?
A. なりません。正規分布に近づくのは標本平均の分布であって、生データ1個1個の分布ではありません。生データの正規性は別途、正規性の検定などで確認します。
まとめ
中心極限定理は、推測統計のほぼすべての土台になっている定理です。要点を整理します。
- 母集団の分布が何であれ、標本平均 \( \bar{x} \) はnが大きいほど正規分布に近づく
- 標本平均の中心は母平均 \( \mu \)、ばらつき(標準誤差)は \( \sigma/\sqrt{n} \)
- nを増やすと標準誤差は小さくなるが、効くのは \( \sqrt{n} \) のぶんだけ(精度2倍にはn4倍)
- 正規分布に近づくのは「平均」であって生データではない
使い分けの一言:個々のばらつきを語るなら標準偏差、平均の推定精度を語るなら標準誤差(σ/√n)。この区別がついていれば、信頼区間も検定も迷いません。
この記事で扱った標本平均の正規分布は、信頼区間の求め方やχ²・t・F分布の使い分けで実際の計算に使われます。あわせて読むと、なぜそれらの手法が成り立つのかが腑に落ちます。
