
「引張強度に影響する要因を同時に特定したい」「ロットを特性の似たグループに分けたい」「複数の品質指標の背後にある因子を探りたい」——こうした分析ニーズが重なるとき、単一の統計手法では対応しきれないことがあります。
この記事では、複数の変数をまとめて扱う「多変量解析」の各手法を目的別に整理します。どの手法を選べばよいかの判断基準と、各手法の詳細解説記事への入口として使ってください。
多変量解析とは
多変量解析は、複数の変数(多変量)を同時に分析する統計手法の総称です。単回帰(1つのXで1つのYを予測)や一元配置分散分析(1要因の比較)と違い、多数の説明変数・複数の結果変数を一括して扱えます。
製造業では次のような場面で活用されます。
- 品質特性(引張強度・硬度・延性)に影響する複数の要因を同時に特定する
- 多数のロットを特性の類似性でグループ化し、工程の傾向をつかむ
- 多数の測定変数の背後にある潜在的な品質因子を見つける
- 良品・不良品を確率で分類するモデルを構築する
手法の2大分類
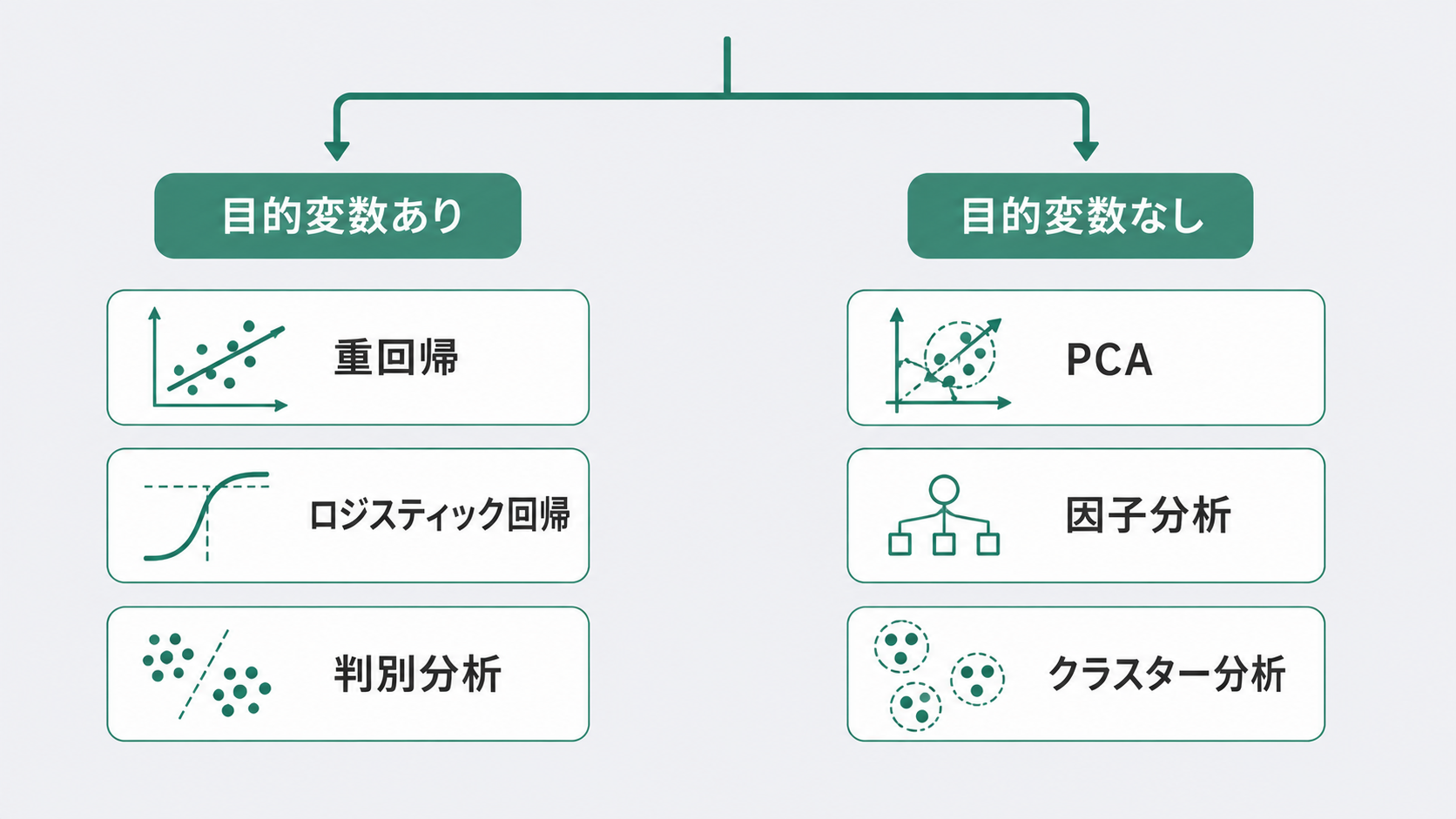
多変量解析は、まず「目的変数(予測・分類したい変数)の有無」で2つに分類されます。ここを間違えると手法選択がずれるので、最初に確認しておく必要があります。
| 分類 | 目的 | 代表的な手法 |
|---|---|---|
| 目的変数あり | Yを予測・分類したい | 重回帰分析・ロジスティック回帰・線形判別分析 |
| 目的変数なし | データの構造・パターンを探りたい | 主成分分析・因子分析・クラスター分析 |
「何かを予測したい」なら目的変数あり、「データを整理・要約したい」なら目的変数なし、と覚えておくと判断しやすくなります。
手法の選び方
目的変数の有無が決まったら、次に「目的変数・説明変数のデータの種類」で手法を絞ります。
| やりたいこと | 目的変数 | 推奨手法 |
|---|---|---|
| 連続変数を複数の要因から予測する | 連続変数(例: 引張強度) | 重回帰分析 |
| 重回帰の変数を自動選択する | 連続変数 | ステップワイズ変数選択 |
| 良否・合否を確率で予測する | 2値変数(0/1) | ロジスティック回帰 |
| 既知のグループに新データを分類する | カテゴリ変数(グループ) | 線形判別分析(LDA) |
| 多変数を少数の合成変数に圧縮する | なし | 主成分分析(PCA) |
| 変数の背後にある潜在因子を見つける | なし | 因子分析 |
| データを自然なグループに分類する | なし | クラスター分析 |
目的変数ありの手法
重回帰分析
複数の説明変数(X₁, X₂, …)から連続変数のY(引張強度・収率など)を予測する手法です。製造業で最も使われる多変量解析の一つで、「どの要因がどれくらい強度に効くか」を偏回帰係数で定量化できます。
注意点として、説明変数間に強い相関がある場合(多重共線性)は係数の解釈が不安定になります。VIFで診断し、問題があれば変数を整理してから使います(詳細は多重共線性(VIF)の診断と解消を参照)。
→ 詳細: 重回帰分析の結果の読み方と変数選択
ステップワイズ変数選択
重回帰分析で「どの変数を残すか」を自動的に決める手法です。前進選択・後退除去・変数増減法の3アルゴリズムがあり、AICや有意水準を基準に最適な変数の組み合わせを探索します。
→ 詳細: ステップワイズ変数選択法|前進選択・後退除去をExcelで実践する手順
ロジスティック回帰
目的変数が「合格/不合格」「良品/不良品」のような2値データの場合に使います。「この条件で不良になる確率は何%か」を0〜1の確率として出力できるのが特徴です。線形回帰で2値データを扱おうとすると予測値が0〜1を外れる問題が起きますが、ロジスティック回帰はそれを回避します。
→ 詳細: ロジスティック回帰分析の基礎|2値データの予測とExcelソルバーでの推定
線形判別分析(LDA)
既知のグループ(設備A/B、材料グレード1/2/3など)が与えられているとき、新しいデータをどのグループに分類するかを決める手法です。グループの分離を最大化する判別関数を計算し、マハラノビス距離で分類します。主成分分析と混同されやすいですが、LDAは「グループを分ける」こと、PCAは「変数を圧縮する」ことが目的です。
→ 詳細: 線形判別分析(LDA)とは|判別関数をExcelで計算する手順
目的変数なしの手法
主成分分析(PCA)
硬度・引張強度・延性・疲労強度など多数の測定変数を、情報をなるべく保ちながら少数の「主成分」に圧縮する手法です。第1主成分・第2主成分の2軸でロットを散布図にプロットすると、データ全体の傾向やグループの分離が視覚的に確認できます。
多重共線性の前処理としても有効で、相関の高い変数群をまとめて1つの主成分として扱うことで重回帰分析の問題を回避できます。
→ 詳細: 主成分分析(PCA)とは|多変量データの次元削減とExcelでの計算手順
因子分析
測定変数の背後にある「潜在因子」を推定する手法です。「硬度・引張強度・疲労強度はすべて材料の強度因子に支配されている」のように、直接観測できない因子を抽出します。主成分分析が「データの分散を最大化する合成変数を作る」のに対し、因子分析は「共通因子の構造を解釈する」ことに重点を置きます。
→ 詳細: 因子分析とは|潜在因子の抽出とExcelでの計算手順
クラスター分析
グループのラベルが与えられていない状態で、データを特性の類似性に基づいて自然なグループ(クラスター)に分類する手法です。「どのロットが似ているか」「工程の状態はいくつのパターンに分かれるか」といった問いに答えます。階層的クラスタリング(ウォード法など)とk-meansの2種類が代表的です。
→ 詳細: クラスター分析とは|ウォード法とk-meansをExcelで実践する
診断・補助ツール
多重共線性(VIF)
多変量解析そのものではなく、重回帰分析・ステップワイズを使う前の「診断ツール」として位置づけます。説明変数間の相関が強すぎると偏回帰係数が不安定になるため、VIF(分散拡大係数)で各変数の問題度を数値化します。VIF>10が変数削除の目安です。
→ 詳細: 多重共線性(VIF)とは|重回帰分析の問題を診断・解消する手順
製造業での活用シナリオ
実際の現場でどの手法を使うか、場面別にまとめます。
| 場面 | 分析の問い | 推奨手法 |
|---|---|---|
| 品質改善 | 引張強度に影響する工程条件はどれか | 重回帰分析 → ステップワイズ |
| 不良予測 | この条件で不良が出る確率は何%か | ロジスティック回帰 |
| 設備判定 | 測定値から設備A/Bのどちらで加工したか判定 | 線形判別分析 |
| データ圧縮 | 10種類の測定値を2〜3軸に圧縮して傾向を把握 | 主成分分析 |
| 品質因子の発見 | 複数の品質特性を支配する潜在的な因子は何か | 因子分析 |
| ロット分類 | 100ロットを品質傾向で自動グループ分け | クラスター分析 |
まとめ
多変量解析の手法選択は、まず「目的変数の有無」で大きく2方向に分かれます。
- 目的変数あり(Yを予測・分類したい)→ 重回帰分析・ロジスティック回帰・線形判別分析
- 目的変数なし(データの構造を探りたい)→ 主成分分析・因子分析・クラスター分析
次に目的変数・説明変数のデータの種類(連続/2値/カテゴリ)で手法を絞れば、選択肢は自然と絞り込まれます。各手法の計算手順・Excelでの実装は、上のリンク先の記事で詳しく解説しています。
統計的検定の選び方については統計的検定の選び方(フロー図付き)、回帰分析の前提確認については回帰分析の前提条件と残差分析もあわせて参照してください。

