
この記事でわかること
- 自由度の直感的な意味(自由に動ける値の個数 = n − 制約の数)
- なぜ標本分散は n ではなく n−1 で割るのか
- t検定・分散分析・χ²検定・F分布それぞれの自由度の求め方
- Excelで臨界値を出すときの自由度の指定方法
📌 前提知識:標準偏差・分散の求め方を読んでいると理解しやすくなります
分散を計算するとき、ふつうの平均は「合計 ÷ 個数」なのに、分散だけはなぜか「平方和 ÷(個数−1)」と教わります。Excelでも STDEV.S はn−1で割り、STDEV.P はnで割る。この「1を引く」の正体が自由度です。
さらにt検定の表を引くときも、分散分析の結果を読むときも、必ず「自由度」という列が出てきます。ここがあいまいなまま手順だけ覚えていると、検定統計量は出せても臨界値の引き方を間違えます。
この記事では、自由度とは何かを「自由に動ける値の個数」というイメージから押さえ、なぜn−1で割るのか、そして各手法での自由度の求め方までを、製造業の数値例で具体的に解説します。
自由度が出てくる場面
自由度は、検定や推定のほぼすべての場面で「分布の形を決めるパラメータ」として登場します。次のような場面では、必ず自由度を正しく数える必要があります。
- 標本から分散・標準偏差を推定するとき:n−1で割る(標準偏差・分散の不偏推定)。
- t検定で臨界値を引くとき:t分布は自由度ごとに形が違うため、自由度を間違えると合否判定がずれる。
- 分散分析でF値を評価するとき:群間・群内それぞれの自由度がF分布の形を決める。
- χ²検定で適合度・独立性を見るとき:カテゴリ数や表のサイズから自由度を計算する。
逆に注意したい点もあります。
(△)自由度は「データの個数 n」そのものではありません。推定した値の数(制約)だけ n から減ります。
(△)同じt検定でも、1標本・対応のない2標本・対応のある2標本で自由度の式が変わります。手順を丸暗記せず、制約の数で考えるのが安全です。
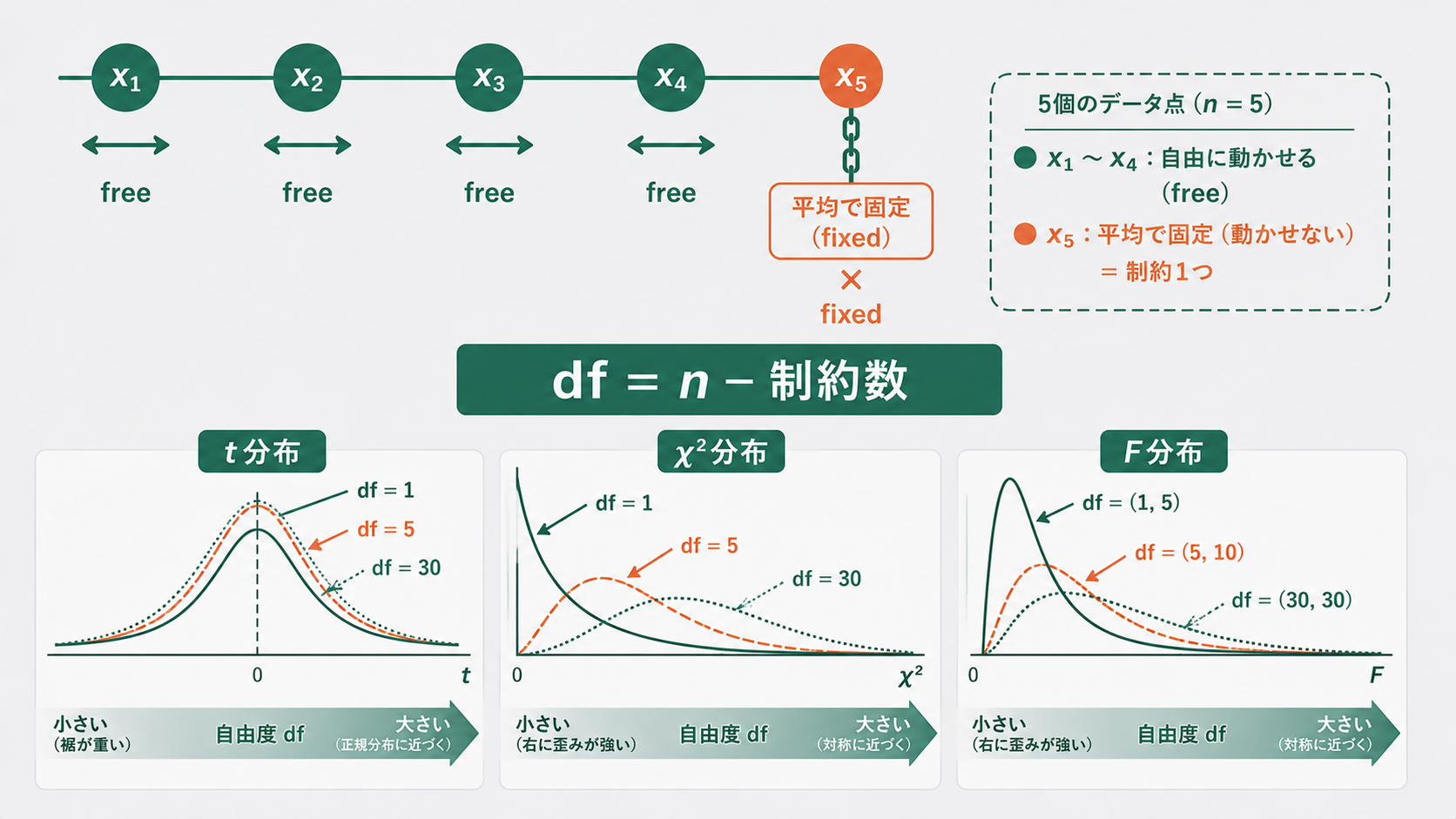
自由度とは(自由に動ける値の個数)
自由度(degrees of freedom, df)は、ひとことで言うと自由に決められる値の個数です。式で書くと次のとおりです。
\[ \text{自由度} = (\text{データの個数}\ n) – (\text{推定した値=制約の数}) \]
イメージをつかむために、5個のデータの平均が 50 だと分かっている状況を考えます。5個のうち4個(たとえば 48, 52, 50, 51)を自由に決めると、平均を50に保つために残り1個は自動的に 49 に決まってしまいます。
つまり「平均を固定する」という1つの制約があると、自由に動かせる値は n 個ではなく n−1 個です。これが自由度 n−1 の正体です。推定した値(ここでは平均)が1つ増えるたびに、自由に動ける余地が1つずつ減っていく、と考えてください。
なぜ標本分散は n−1 で割るのか
標本分散の式は、偏差の平方和を n−1 で割る形です。
\[ s^2 = \frac{\sum (x_i – \bar{x})^2}{n – 1} \]
Excelでは標本(n−1で割る)と母集団(nで割る)で関数が分かれています。
標本分散(n−1で割る): =VAR.S(範囲)
母集団分散(nで割る) : =VAR.P(範囲)
標準偏差なら : =STDEV.S(範囲) / =STDEV.P(範囲)なぜ n ではなく n−1 なのか。理由は、偏差 \( x_i – \bar{x} \) を計算する時点で、すでに標本平均 \( \bar{x} \) を使ってしまっているからです。偏差の合計は必ず 0 になるという制約があり、その制約のぶん自由度が1つ減ります。
具体例で見てみましょう。ある部品の引張強度を5本測ったら 48, 52, 50, 51, 49(MPa)でした。平均は 50 です。各偏差は次のとおりです。
| 測定値 | 偏差 (x − 50) | 偏差² |
|---|---|---|
| 48 | −2 | 4 |
| 52 | +2 | 4 |
| 50 | 0 | 0 |
| 51 | +1 | 1 |
| 49 | −1 | 1 |
| 合計 | 0 | 10 |
偏差の合計はぴったり 0 です。これが「1つの制約」で、5個のうち4個が決まれば5個目は自動で決まります。だから自由度は 5−1 = 4。平方和10をこの自由度で割って、
\[ s^2 = \frac{10}{4} = 2.5 \]
もし誤って n=5 で割ると 10/5 = 2.0 となり、分散を小さめに見積もってしまいます。n−1 で割ることで、この過小評価の偏りが補正されます。これを不偏分散と呼びます。
各検定での自由度の求め方
手法ごとに「いくつの値を推定したか」で自由度が決まります。代表的な検定の自由度を整理します。
| 手法 | 自由度の式 | 例 |
|---|---|---|
| 1標本t検定 | n − 1 | n=10 → df=9 |
| 対応のない2標本t検定(等分散) | n₁ + n₂ − 2 | n₁=8, n₂=10 → df=16 |
| χ²適合度検定 | k − 1 −(推定したパラメータ数) | k=4・推定なし → df=3 |
| χ²独立性検定 | (行−1)(列−1) | 2×3表 → df=2 |
| 一元配置分散分析 | 群間 k−1 / 群内 N−k | 後述 |
t検定の自由度
1標本t検定では平均を1つ推定するので df = n−1。対応のない2標本では、2つの群それぞれで平均を推定するため制約が2つになり、df = n₁ + n₂ − 2 です。たとえば n₁=8、n₂=10 なら、
\[ df = 8 + 10 – 2 = 16 \]
χ²検定の自由度
適合度検定では、カテゴリが k 個あると基本の自由度は k−1 です。さらに分布のパラメータ(平均や比率など)を標本から推定した場合は、その数だけ引きます。独立性検定(クロス集計表)では、行数 r・列数 c から df = (r−1)(c−1) で求めます。2行3列の表なら、
\[ df = (2-1)(3-1) = 2 \]
分散分析・F分布の自由度
一元配置分散分析では、自由度が2種類出てきます。水準(群)の数を k、総データ数を N とすると、群間(要因)の自由度は k−1、群内(誤差)の自由度は N−k です。両者を足すと全体の自由度 N−1 です。
たとえば3つの装置(k=3)から各5個ずつ、合計 N=15 個を測った場合は次のとおりです。
- 群間(要因)の自由度:k − 1 = 3 − 1 = 2
- 群内(誤差)の自由度:N − k = 15 − 3 = 12
- 全体の自由度:N − 1 = 14(= 2 + 12 で一致)
分散分析の検定統計量Fは、群間と群内の分散の比です。F分布は分子と分母の2つの自由度で形が決まるため、この例なら F(2, 12) の分布と比較します。どの分布(t・χ²・F)を使うかはχ²・t・F分布の使い分けで整理しています。
Excelで臨界値を出すときの自由度
検定では、検定統計量と比べる「臨界値」を求めるときに自由度を引数で渡します。Excelの逆関数を使うと、表を引かずに臨界値が出せます。
有意水準5%(両側)・自由度9のt臨界値:
=T.INV.2T(0.05, 9)
→ 2.262有意水準5%・自由度3のχ²臨界値(上側):
=CHISQ.INV.RT(0.05, 3)
→ 7.815有意水準5%・自由度(2, 12)のF臨界値(上側):
=F.INV.RT(0.05, 2, 12)
→ 3.885いずれも引数に自由度が入っています。ここを間違えると、同じデータでも合否がひっくり返ります。検定統計量を出したら、対応する自由度を必ずセットで確認してください。信頼区間を求めるときも、同じくt分布の自由度 n−1 を使います。
QC検定での問われ方とミニ例題
QC検定では、自由度は2級・3級の検定・推定や分散分析で必ず問われます。とくに分散分析表の自由度の欄を埋める問題や、t検定の自由度 n−1 を答える問題が頻出です。
よく問われるポイントは次の3つです。
- 標本分散・不偏分散は平方和を n−1 で割る(自由度 n−1)
- 一元配置分散分析の群間 df=k−1、群内 df=N−k、足すと N−1
- 対応のない2標本t検定の df は n₁+n₂−2
ミニ例題:4台の装置から各6個ずつ、合計24個の特性値を測り、一元配置分散分析を行う。群間・群内・全体の自由度はそれぞれいくつか。
解答:水準数 k=4、総数 N=24 です。群間の自由度は k−1 = 4−1 = 3。群内の自由度は N−k = 24−4 = 20。全体の自由度は N−1 = 23 で、3 + 20 = 23 と一致します。分散分析表の自由度の欄は、この「足すと全体になる」関係でいつも検算できます。
よくある質問(FAQ)
Q. 自由度は必ず整数になりますか?
A. 多くの検定では整数ですが、等分散を仮定しないウェルチのt検定だけは自由度が小数をとります。近似計算のため、Excelの T.TEST などが内部で小数の自由度を使います。
Q. なぜ自由度が大きいほどt分布は正規分布に近づくのですか?
A. 自由度が大きい=標本が大きいほど、分散の推定が安定するためです。自由度が無限大の極限で、t分布は標準正規分布と一致します。
Q. STDEV.S と STDEV.P はどちらを使えばよいですか?
A. 手元のデータが「母集団全体」なら STDEV.P(nで割る)、母集団から抜き取った「標本」なら STDEV.S(n−1で割る)です。品質管理で母集団を推定したい場面では、ほぼ STDEV.S を使います。
まとめ
自由度は、検定や推定で「分布の形」と「割る数」を決める基本量です。要点を整理します。
- 自由度 = データの個数 n − 推定した値(制約)の数
- 標本分散を n−1 で割るのは、偏差の合計が0という制約で自由度が1つ減るから
- t検定は n−1(2標本なら n₁+n₂−2)、χ²独立性は (行−1)(列−1)、分散分析は群間 k−1・群内 N−k
- Excelの T.INV・CHISQ.INV・F.INV では自由度を引数で渡す
使い分けの一言:「いくつの値を先に推定したか」を数えれば、その数だけ n から引くのが自由度。手順の丸暗記ではなく制約の数で考えると、どの検定でも迷いません。
この記事で扱った自由度は、母分散の検定・推定やχ²・t・F分布の使い分けで実際の計算に使われます。あわせて読むと、なぜそれぞれの分布で自由度の数え方が変わるのかが腑に落ちます。
