
この記事でわかること
- 母集団と標本の違いと、なぜ一部の標本から全体を推し量れるのか
- 母数(μ・σ²・P)と統計量(x̄・s²・p)の対応と記号の使い分け
- 記述統計と推測統計の違い
- 偏りのないサンプリングがなぜ重要か
📌 前提知識:標準偏差・分散の求め方を知っていると理解がスムーズです
受け入れたロット10,000個の中に、規格外の部品がどれくらい混ざっているか知りたい。でも、全部を測って検査するのは時間もコストも現実的ではありません。そこで100個だけ抜き取って調べ、その結果からロット全体を判断します。
この「全部は測れないから一部で代表させる」という考え方が、統計のいちばん土台にある発想です。調べたい全体が母集団、実際に手元で調べる一部が標本です。
この記事では、母集団と標本の違い、両者をつなぐ母数と統計量、そして「なぜ一部から全体を語れるのか」という推測統計の考え方を、製造業の抜取検査を例に解説します。
母集団と標本を区別する場面
次のような場面では、いま自分が見ている数値が「母集団の値」なのか「標本の値」なのかを、はっきり区別する必要があります。
- 抜取検査で合否を判断するとき:抜き取った標本の不良率から、ロット全体(母集団)の品質を推定する。
- 工程の平均や分散を推定するとき:測った数個から、工程全体(母集団)の母平均・母分散を見積もる。
- 検定や区間推定を行うとき:標本のデータをもとに、母集団について結論を出す。
逆に注意したい点もあります。
(△)手元のデータが「知りたい全体そのもの」なら、それは標本ではなく母集団です。推定は不要で、そのまま記述すれば済みます。
(△)標本の平均(統計量)と母集団の平均(母数)は別物です。標本平均はあくまで母平均の推定値で、ぴったり一致するとは限りません。
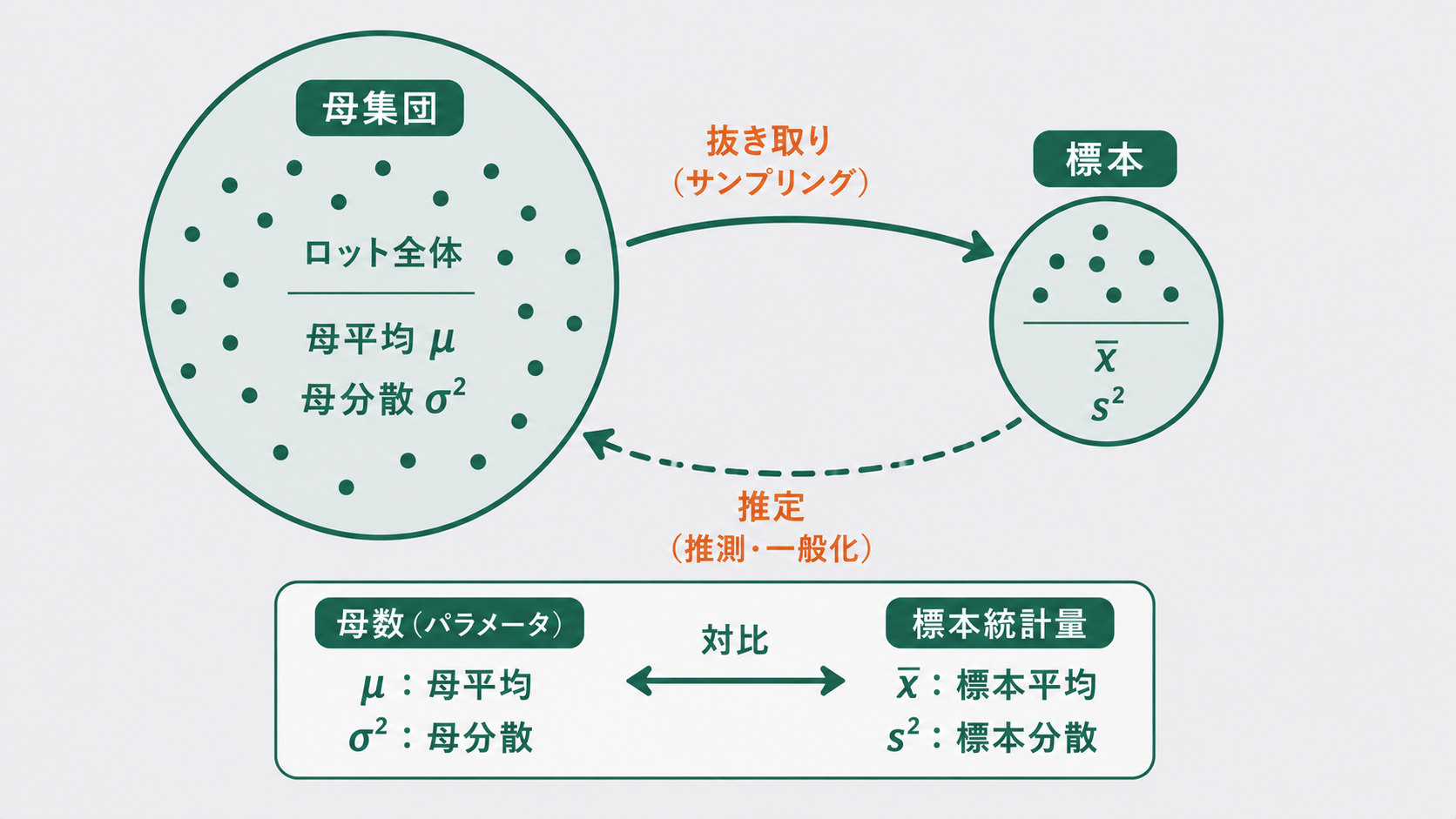
母集団と標本とは
母集団とは、調べたい対象の全体です。標本(サンプル)とは、その母集団から実際に抜き取って調べる一部です。
全部を調べることを全数調査、一部を抜き取って調べることを標本調査と呼びます。製造業の検査でいえば、ロット全数を測るのが全数調査、一部を抜き取るのが標本調査(抜取検査)です。
なぜ一部で済ませるのか。理由は主に3つあります。
- 全数調査はコストと時間がかかりすぎる(10,000個を全部測るのは非現実的)
- 破壊検査では全数を調べると製品が残らない(引張強度試験など)
- 適切に抜き取れば、一部からでも全体を十分な精度で推定できる
3つ目が統計のキモです。標本平均が母平均にどれだけ近づくか、どのくらいの誤差で推定できるかは、統計理論できちんと評価できます。だからこそ「一部を見て全体を語る」ことに根拠が生まれます。
母数と統計量(μ・σ² と x̄・s²)
母集団の特徴を表す値を母数(パラメータ)、標本から計算した値を統計量と呼びます。両者はペアになっていて、記号で区別します。母数はギリシャ文字、統計量はローマ字(アルファベット)を使うのが慣習です。
| 意味 | 母数(母集団・ギリシャ文字) | 統計量(標本・ローマ字) |
|---|---|---|
| 平均 | 母平均 μ | 標本平均 x̄ |
| 分散 | 母分散 σ² | 標本分散 s² |
| 標準偏差 | 母標準偏差 σ | 標本標準偏差 s |
| 比率 | 母比率 P | 標本比率 p |
母数は「本当に知りたいが、ふつう直接は分からない値」です。一方の統計量は「標本から実際に計算できる値」で、母数を推定するための材料です。
たとえば、あるロットから内径を5個抜き取ったら 10.1, 9.8, 10.0, 10.2, 9.9(mm)でした。標本平均は
\[ \bar{x} = \frac{10.1 + 9.8 + 10.0 + 10.2 + 9.9}{5} = 10.0 \]
Excelでは =AVERAGE(範囲) で求めます。この 10.0mm が統計量で、まだ分からない母平均 μ の推定値です。標本分散 s² も同様に、標準偏差・分散の式で計算すると母分散 σ² の推定に使えます(Excelは =VAR.S(範囲)、この例では 0.025)。
記述統計と推測統計の違い
統計には大きく2つの立場があります。手元のデータをそのまま要約する記述統計と、標本から母集団を推し量る推測統計です。
| 観点 | 記述統計 | 推測統計 |
|---|---|---|
| 目的 | データの特徴を要約する | 標本から母集団を推定・判断する |
| 対象 | 手元のデータそのもの | 背後にある母集団 |
| 代表的な手法 | 平均・中央値・標準偏差・グラフ | 推定・検定 |
記述統計は「測ったものを分かりやすくまとめる」だけで、母集団の話は出てきません。推測統計になると、標本という限られた情報から、その先にある母集団について結論を出します。検定や推定が推測統計にあたります。
標本から母集団を推し量る(推定と検定)
推測統計で母集団に踏み込む方法は、大きく推定と検定に分かれます。
- 点推定:母数をひとつの値でズバリ見積もる。標本平均 x̄ を母平均 μ の推定値とする、など。
- 区間推定:母数が入りそうな範囲を示す。95%信頼区間が代表例。
- 検定:母集団について立てた仮説を、標本データで検証する。仮説検定の手順で判断する。
たとえばロット500個から50個を抜き取り、不良が2個だったとします。標本不良率は
\[ p = \frac{2}{50} = 0.04 \]
この 0.04(4%)が標本比率という統計量で、母比率 P の点推定値です。Excelでは単純に =2/50 で計算できます。ただし別の50個を抜けば結果は変わるため、「母比率はぴったり4%」とは言い切れません。そこで区間推定や検定を使い、誤差を見込んだうえで母集団について語ります。母分散についての推定・検定は母分散の検定・推定で扱っています。
偏りのない標本を取る(サンプリング)
推測統計が成り立つ大前提は、標本が母集団を偏りなく代表していることです。偏った標本から推定すると、どれだけ計算が正しくても結論はずれます。
たとえば、ライン立ち上げ直後の不安定な時間帯だけで抜き取れば、不良率を高めに見積もってしまいます。逆に調子のよい時間帯だけを選べば、品質を過大評価します。こうした偏り(バイアス)を避けるため、どの製品も等しい確率で選ばれるようにするランダムサンプリング(無作為抽出)が基本です。
抜き取り方には単純無作為・系統・層別などいくつかの方式があります。それぞれの使い分けはサンプリングの種類で解説しています。
QC検定での問われ方とミニ例題
QC検定では、母集団と標本の区別、母数と統計量の対応が「データの取り方・まとめ方」の基礎として頻出です。とくに母数はギリシャ文字(μ・σ)、統計量はローマ字(x̄・s)という記号の対応がよく問われます。
よく問われるポイントは次の3つです。
- 母集団の値が母数(μ・σ²・P)、標本から計算した値が統計量(x̄・s²・p)
- 全部を調べるのが全数調査、一部を抜き取るのが標本調査
- 標本平均は母平均の推定値であり、両者は一致するとは限らない
ミニ例題:あるロットから100個を無作為に抜き取り、平均長さ 25.3mm・不良3個という結果を得た。(1) この 25.3mm は母数か統計量か。(2) ロット全数を測ることを何と呼ぶか。
解答:(1) 標本から計算した値なので統計量(標本平均 x̄)です。本当に知りたいロット全体の平均 μ(母数)の推定値にあたります。(2) 全数調査です。なお標本不良率は 3/100 = 0.03(3%)で、これも母不良率 P の点推定値となる統計量です。
よくある質問(FAQ)
Q. 標本と母集団、どちらの分散を使うべきですか?
A. 母集団全体のデータがそろっているなら母分散(nで割る・VAR.P)、母集団から抜き取った標本から推定するなら標本分散(n−1で割る・VAR.S)です。品質管理で母集団を推定したい場面では、ほぼ標本分散を使います。
Q. 標本は何個あればよいですか?
A. 求めたい精度(許容できる誤差)と母集団のばらつきで決まります。精度を上げたいほど多くの標本が必要です。サンプルサイズの設計は専用の計算で求めます。
Q. 母数と変数は同じ意味ですか?
A. 違います。母数は母集団の特徴を表す定数(母平均μなど)で、変数は個々のデータがとる値です。「母数」を「分母」や「全体の個数」の意味で使う日常語とも別物なので注意してください。
まとめ
母集団と標本の区別は、推測統計のすべての出発点です。要点を整理します。
- 母集団は調べたい全体、標本はそこから抜き取った一部
- 母数(μ・σ²・P)はギリシャ文字、統計量(x̄・s²・p)はローマ字で表す
- 記述統計は手元のデータの要約、推測統計は標本から母集団を推定・判断する立場
- 推定や検定が成り立つ前提は、偏りのないランダムサンプリング
使い分けの一言:知りたい全体が母集団、手元で測れる一部が標本。ギリシャ文字なら母数、ローマ字なら統計量。この対応が頭に入っていれば、推定も検定も迷いません。
母集団を推し量る具体的な方法は、信頼区間の求め方やサンプリングの種類で解説しています。あわせて読むと、標本から母集団へ橋を架ける流れがつかめます。
