「p値が0.05より小さければ有意差あり」——現場でそう使っているけど、p値が何を意味する数字なのかは曖昧なまま、という人は少なくない。
この記事ではp値の意味を一から整理します。2工程の引張強度比較を例に、計算の手順・Excelでの求め方・よくある誤解まで解説します。
p値とは何か
p値の定義はこうです。
帰無仮説が正しいと仮定したとき、今回の実験結果と同じかそれ以上に極端な結果が偶然起きる確率
言い換えると、「もし2つの工程に本当に差がないなら、これほどの差がデータに出る確率はどのくらいか」という数字です。
p値が小さいほど、「差がないという前提でこの結果が出るのは考えにくい」→「実は差があるのかもしれない」という判断につながります。
具体例で確認する
2つの工程ラインで同じ部品を製造し、引張強度を各8個ずつ測定しました。
| 工程 | サンプル数 | 平均(MPa) | 標準偏差(MPa) |
|---|---|---|---|
| 工程A(新プロセス) | 8 | 502 | 4.5 |
| 工程B(旧プロセス) | 8 | 495 | 5.2 |
平均の差は7MPa。でもこれは測定ばらつきの範囲内なのか、それとも本当に工程の違いを反映しているのか——t検定とp値で判断します。
Step 1:仮説を立てる
- 帰無仮説 H₀:2工程の母平均に差はない(μA = μB)
- 対立仮説 H₁:2工程の母平均に差がある(μA ≠ μB)
- 有意水準:α = 0.05
Step 2:t統計量を計算する
等分散の2標本t検定を使います。まず合併標準偏差 \( S_p \) を計算します。\[ S_p = \sqrt{\frac{(n_A-1)s_A^2 + (n_B-1)s_B^2}{n_A+n_B-2}} = \sqrt{\frac{7 \times 4.5^2 + 7 \times 5.2^2}{14}} = 4.863 \]
次に標準誤差と t 統計量を求めます。\[ SE = S_p \sqrt{\frac{1}{n_A}+\frac{1}{n_B}} = 4.863 \times \sqrt{\frac{1}{8}+\frac{1}{8}} = 2.431 \] \[ t = \frac{\bar{x}_A – \bar{x}_B}{SE} = \frac{502 – 495}{2.431} = 2.879 \]
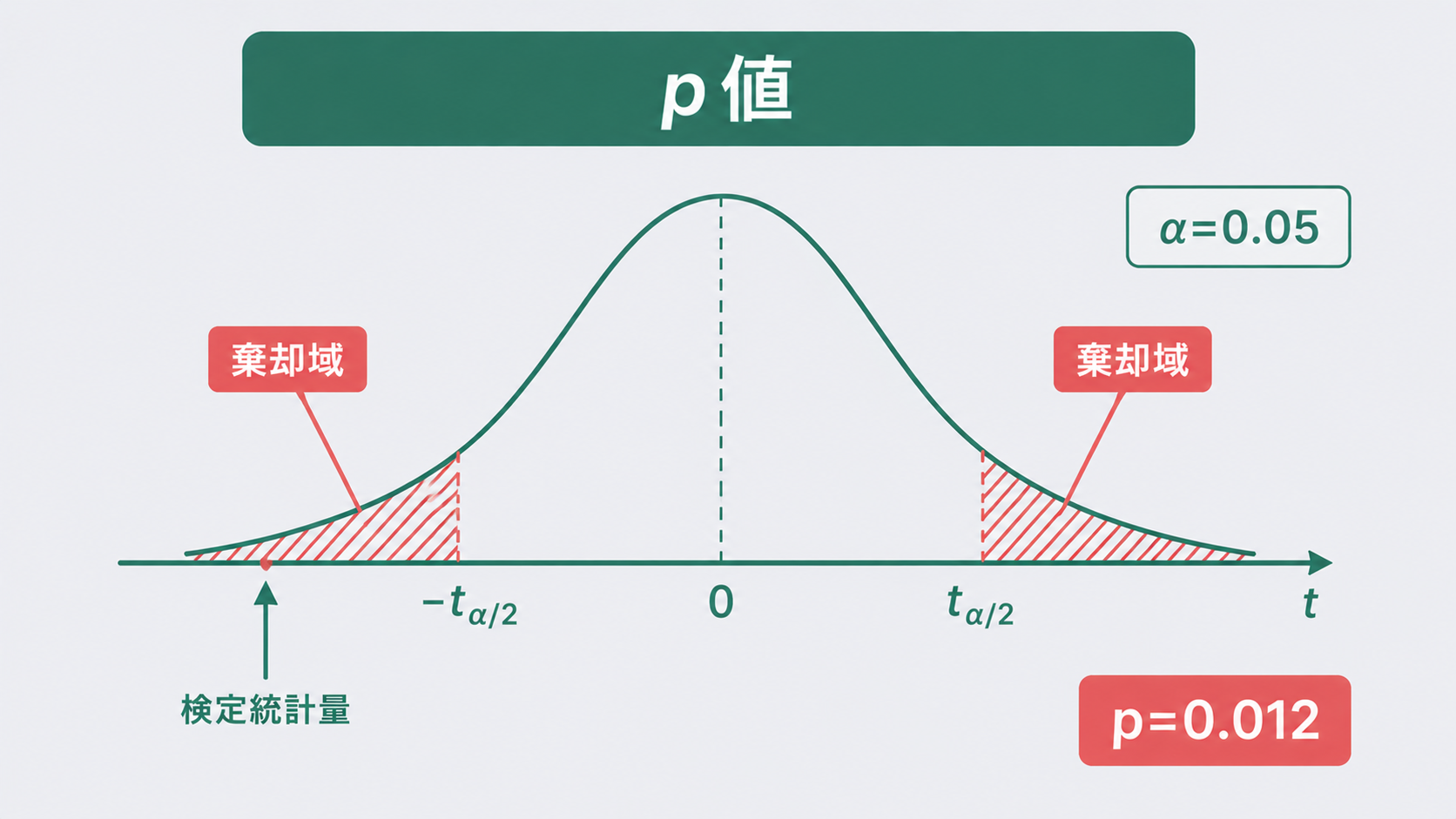
Step 3:p値を求める
自由度 df = nA + nB − 2 = 14 の t 分布で、t = 2.879 以上(または以下)になる確率を求めます。これが両側p値です。\[ p = P(|T| \geq 2.879) = 0.0121 \]
Step 4:判定する
p = 0.0121 < α = 0.05 → 帰無仮説を棄却します。
2工程の引張強度に有意差があります(p = 0.012)。工程Aの方が平均7MPa高く、その差は統計的に偶然と言えないレベルです。
p値が大きい場合との比較
別の設定で確認します。工程Cと工程Dを比較した場合です。
| 工程 | サンプル数 | 平均(MPa) | 標準偏差(MPa) |
|---|---|---|---|
| 工程C | 8 | 500 | 5.5 |
| 工程D | 8 | 495 | 5.0 |
平均の差は同じ5MPa。ただしばらつきが大きく、t = 1.903、p = 0.077 となります。
p = 0.077 > α = 0.05 → 帰無仮説を棄却できません。
「差があると言えない」——これは「差がない」とは違います。データが少なく、ばらつきが大きいために差の有無を断言できない、という意味です。
有意水準α = 0.05はどこから来たか
「p < 0.05で有意差あり」という基準は、統計学者ロナルド・フィッシャーが1925年に提案した慣習です。「20回に1回以下しか起きない偶然なら、偶然ではないと判断してよい」という考え方から来ています。
医薬品の臨床試験では α = 0.01、探索的な研究では α = 0.10 を使うこともあります。0.05が唯一の正解ではなく、研究の目的とリスクに応じて設定するものです。
α と p値の関係を整理します。
| 有意水準 α | 対応する棄却域(df=14) | 使われる場面 |
|---|---|---|
| 0.10 | t > 1.761 | 探索的研究、スクリーニング |
| 0.05 | t > 2.145 | 一般的な工業・研究 |
| 0.01 | t > 2.977 | 医薬品、安全基準 |
p値についてのよくある誤解
p値は実務でも研究でも、よく誤解されます。代表的な誤解を3つ挙げます。
誤解①「p値は帰無仮説が正しい確率」
違います。p値は「帰無仮説が正しいと仮定したときのデータの確率」です。仮説の確率そのものではありません。
誤解②「p < 0.05なら実用的に重要な差がある」
p値は統計的な有意性を示すだけで、差の大きさ(効果量)は別の話です。n が大きければ、実用的に意味のない小さな差でもp < 0.05になります。効果量の評価は効果量(Cohen’s d・η²)の求め方を参照してください。
誤解③「p > 0.05なら差がない」
違います。「差がないとは言えない」です。検出力(サンプルサイズ・ばらつき)が不十分なだけで、差が存在する可能性は排除できません。サンプルサイズの設計はサンプルサイズの決め方を参照してください。
片側検定と両側検定のp値
上の例は「差があるか」を問う両側検定でした。「工程Aの方が高いか」のように方向を問う場合は片側検定を使います。
| 検定の種類 | 仮説の方向 | p値の求め方 |
|---|---|---|
| 両側検定 | μA ≠ μB(差がある) | 両裾の面積の合計 |
| 片側検定(右) | μA > μB(Aの方が高い) | 右裾の面積のみ |
| 片側検定(左) | μA < μB(Aの方が低い) | 左裾の面積のみ |
片側検定のp値は両側検定の半分になります。上の例(t = 2.879, 両側p = 0.0121)で「工程Aが高い」方向の片側検定をすると p = 0.006 です。方向を事前に決めずに検定してから都合の良い方を使う、いわゆる「後付け片側検定」は統計的に不適切です。検定の種類は事前に決めてください。
Excelでp値を求める
Excelの分析ツールを使う場合、回帰分析・t検定・分散分析のいずれも出力結果に「P値」の列が含まれます。
関数で直接求める方法もあります。
| 場面 | Excel関数 |
|---|---|
| t統計量からp値(両側) | =T.DIST.2T(ABS(t値), 自由度) |
| t統計量からp値(右片側) | =T.DIST.RT(t値, 自由度) |
| F統計量からp値 | =F.DIST.RT(F値, df1, df2) |
| χ²統計量からp値 | =CHISQ.DIST.RT(χ²値, 自由度) |
上の例なら =T.DIST.2T(2.879, 14) で 0.0121 が得られます。
📚 合わせて読みたい書籍
完全独習 統計学入門(小島 寛之)— 数式を最小限に抑えた統計学の入門書。検定の考え方を基礎から学べます。
マンガでわかる統計学(高橋 信)— マンガ形式でとにかくわかりやすい超入門書。統計学が初めての方に。
まとめ
p値は「帰無仮説が正しいとした場合に、今回と同じかそれ以上に極端な結果が偶然起きる確率」です。
- p < α(有意水準)なら帰無仮説を棄却 → 有意差あり
- p ≥ α なら帰無仮説を棄却できない → 「差がないと証明された」ではない
- 有意水準α = 0.05 はフィッシャーの慣習。研究目的に応じて変えてよい
- p値は統計的な有意性だけを示す。実用的な重要性(効果量)は別に評価する
p値は仮説検定のすべての手法で登場します。t検定はt検定とは?、分散分析は一元配置分散分析、カイ二乗検定はカイ二乗検定(χ²検定)とはを参照してください。検定全体の選び方は統計的検定の選び方(フロー図付き)にまとめてあります。