
正規性の確認で「分布が正規分布に従っているとは言えない」と判断されたとき、 t検定や分散分析の代わりに使うのがノンパラメトリック検定です。 この記事では、Python の scipy.stats を使って代表的な4つの検定を実行する方法をまとめます。 どの検定をいつ使うかの選択ポイントも含めて整理しました。
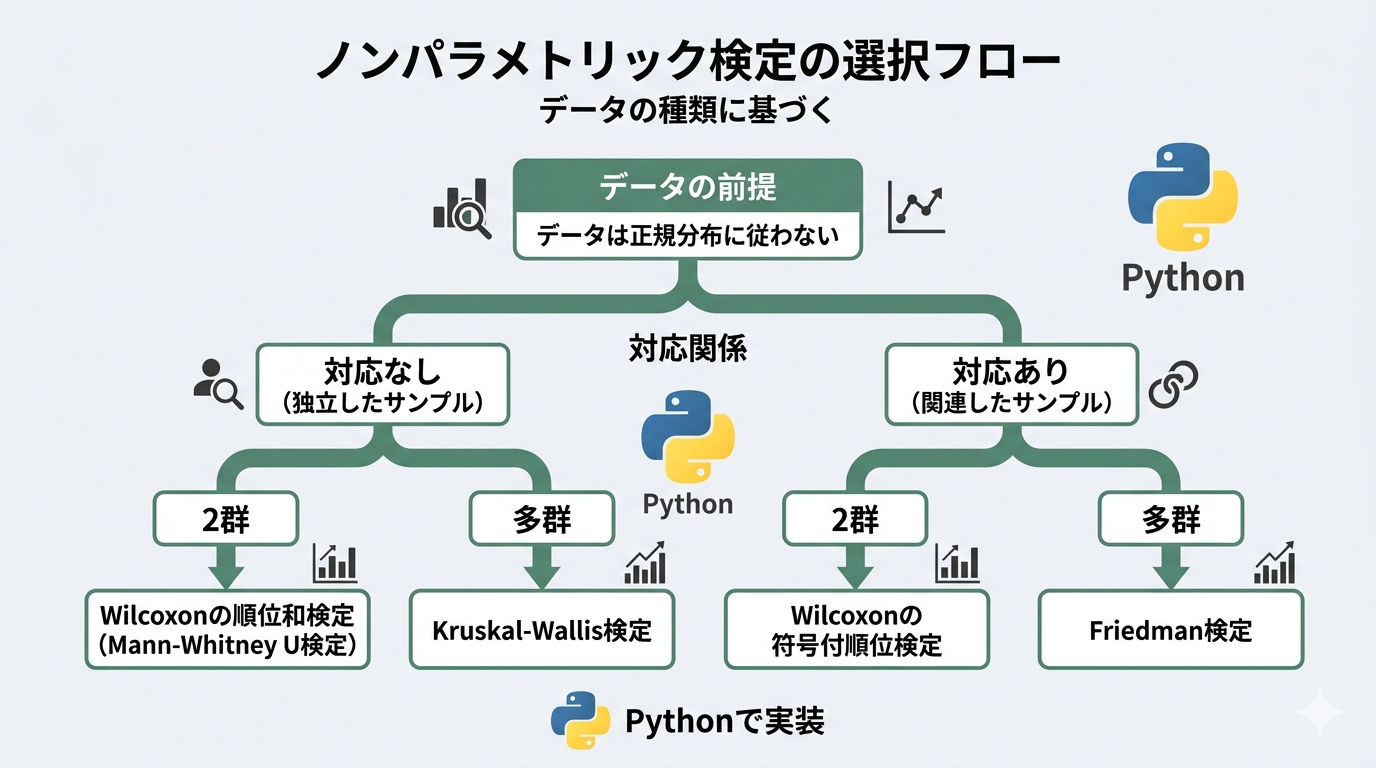
検定の選び方:まずここで整理する
どのノンパラメトリック検定を使うかは、次の2点で決まります。
- 比較するグループ数:2群 or 3群以上
- 対応の有無:同一個体の前後比較(対応あり)か、独立した別グループの比較(対応なし)か
| 2群の比較 | 3群以上の比較 | |
|---|---|---|
| 対応なし(独立した群) | マン・ホイットニー U 検定mannwhitneyu | クルスカル・ワリス検定kruskal |
| 対応あり(同一個体・反復) | ウィルコクソン符号順位検定wilcoxon | フリードマン検定friedmanchisquare |
正規性の確認方法はシャピロウイルク検定で正規性を確認するの記事を、 検定手法全体の選び方は統計的検定の選び方(フロー図付き)を参照してください。
共通の前準備:ライブラリのインポート
import numpy as np
from scipy import stats
4つの検定すべて scipy.stats の関数で実行できます。追加のインストールは不要です。
① マン・ホイットニー U 検定:対応なし2群
使う場面
2つの独立したグループの中央値を比較したいとき。 t検定の「正規性」の仮定が成り立たない場合の代替手法です。 製造業では「製造ラインAとラインBで品質に差があるか」「処理方法の違いで測定値の中央値が変わるか」といったケースに使います。
例題データ
ラインAとラインBで製造した部品の引張強度(MPa)を比較します。
line_a = [42.1, 38.5, 45.3, 40.2, 43.8, 39.6, 44.5, 41.0, 46.2, 38.9]
line_b = [47.3, 50.1, 48.6, 45.9, 51.2, 49.0, 46.8, 52.3, 48.1, 50.7]
検定の実行
stat, p_value = stats.mannwhitneyu(line_a, line_b, alternative='two-sided')
print(f"U統計量: {stat:.1f}")
print(f"p値: {p_value:.4f}")
print(f"判定: {'有意差あり' if p_value < 0.05 else '有意差なし'} (α=0.05)")
# 出力例
U統計量: 2.0
p値: 0.0002
判定: 有意差あり (α=0.05)
引数の説明
alternative='two-sided':両側検定(「どちらが大きいかわからない」場合。通常はこれを使う)alternative='greater':片側検定(line_a の方が大きいと仮定する場合)alternative='less':片側検定(line_a の方が小さいと仮定する場合)
p値が 0.05 未満なので、ラインAとラインBの引張強度には統計的に有意な差があると判断できます。
② ウィルコクソン符号順位検定:対応あり2群
使う場面
同一サンプルや同一個体で処理前後を比較するとき。 「改善前と改善後で同じ製品の測定値に差があるか」「同じ試験片を2つの測定機器で測って差があるか」といった場面です。
例題データ
15個の部品について、表面処理前後の硬度(HV)を測定しました。
before = [52, 48, 55, 50, 47, 53, 49, 51, 46, 54, 50, 48, 52, 49, 53]
after = [58, 55, 60, 57, 54, 59, 56, 58, 52, 61, 57, 55, 59, 56, 60]
検定の実行
stat, p_value = stats.wilcoxon(before, after, alternative='two-sided')
print(f"W統計量: {stat:.1f}")
print(f"p値: {p_value:.4f}")
print(f"判定: {'有意差あり' if p_value < 0.05 else '有意差なし'} (α=0.05)")
# 出力例
W統計量: 0.0
p値: 0.0001
判定: 有意差あり (α=0.05)
表面処理によって硬度が有意に変化したと判断できます。 差がゼロのデータペアがある場合、デフォルトでは除外されます(zero_method='wilcox')。
③ クルスカル・ワリス検定:対応なし3群以上
使う場面
3つ以上の独立したグループを比較するとき。 一元配置分散分析の正規性が満たされない場合の代替手法です。 「3種類の添加剤で収率に違いがあるか」「4つの製造拠点で品質に差があるか」といったケースです。
例題データ
3種類の添加剤(A・B・C)を使用した際の反応収率(%)を比較します。
additive_a = [78.2, 80.1, 77.5, 79.8, 81.3, 76.9, 80.5]
additive_b = [83.4, 85.2, 82.8, 84.6, 86.1, 83.0, 85.5]
additive_c = [75.1, 73.8, 76.4, 74.2, 77.0, 73.5, 75.8]
検定の実行
stat, p_value = stats.kruskal(additive_a, additive_b, additive_c)
print(f"H統計量: {stat:.4f}")
print(f"p値: {p_value:.4f}")
print(f"判定: {'グループ間に有意差あり' if p_value < 0.05 else 'グループ間に有意差なし'} (α=0.05)")
# 出力例
H統計量: 18.0816
p値: 0.0001
判定: グループ間に有意差あり (α=0.05)
どのグループ間に差があるか:多重比較
クルスカル・ワリス検定は「少なくとも1組のグループ間に差がある」ことしかわかりません。 どのペアに差があるかを調べるには、多重比較が必要です。 ノンパラメトリックの多重比較には Dunn 検定が使われます。
from scipy.stats import mannwhitneyu
from itertools import combinations
groups = {'A': additive_a, 'B': additive_b, 'C': additive_c}
pairs = list(combinations(groups.keys(), 2))
print("ペアワイズ比較(ボンフェローニ補正あり):")
n_tests = len(pairs)
for g1, g2 in pairs:
stat, p = mannwhitneyu(groups[g1], groups[g2], alternative='two-sided')
p_adjusted = min(p * n_tests, 1.0) # ボンフェローニ補正
sig = '✔ 有意' if p_adjusted < 0.05 else '有意でない'
print(f" {g1} vs {g2}: p(補正後)={p_adjusted:.4f} → {sig}")
多重比較の理論的な背景は多重比較法とは?種類と選び方・ Pythonで多重比較法(statsmodels)もあわせて参照してください。
④ フリードマン検定:対応あり3群以上
使う場面
同一個体や同一ブロックに対して3つ以上の条件を比較するとき。 反復測定分散分析の正規性が満たされない場合の代替手法です。 「3種類の評価基準で同じサンプルを評価したとき、評価者間に系統的な違いがあるか」「4つの処理順序で同じ被験体の結果に差があるか」といった場面に使います。
例題データ
10台の試験装置で、3種類の測定プロトコル(X・Y・Z)を使って同じ標準サンプルの硬度を測定しました。
# 各行が1台の装置(同一ブロック)、各列がプロトコル
protocol_x = [50.1, 48.3, 51.2, 49.7, 52.0, 48.8, 50.5, 49.2, 51.8, 50.3]
protocol_y = [52.4, 50.8, 53.5, 52.1, 54.3, 51.2, 52.9, 51.6, 54.0, 52.7]
protocol_z = [49.3, 47.5, 50.1, 48.6, 51.0, 47.8, 49.5, 48.1, 50.8, 49.4]
検定の実行
stat, p_value = stats.friedmanchisquare(protocol_x, protocol_y, protocol_z)
print(f"χ²統計量: {stat:.4f}")
print(f"p値: {p_value:.4f}")
print(f"判定: {'プロトコル間に有意差あり' if p_value < 0.05 else 'プロトコル間に有意差なし'} (α=0.05)")
# 出力例
χ²統計量: 20.0000
p値: 0.0000
判定: プロトコル間に有意差あり (α=0.05)
測定プロトコルによって有意な差があることが確認されました。 どのプロトコル間に差があるかは、ウィルコクソン検定でペアワイズ比較を行い、ボンフェローニ補正を適用して判断します。
効果量の計算:有意差があっても「どのくらい違うか」を示す
p値が小さくても、実際の差が実務的に意味のある大きさかどうかは別問題です。 ノンパラメトリック検定では、U統計量から効果量 r を計算できます。\[ r = \frac{Z}{\sqrt{N}} \]
\(Z\) はz変換した統計量、\(N\) は全データ数です。r の目安は 0.1(小)・0.3(中)・0.5(大)です。
# マン・ホイットニー U 検定の効果量
n1, n2 = len(line_a), len(line_b)
N = n1 + n2
z_score = stats.norm.ppf(p_value / 2) # 両側検定
r = abs(z_score) / np.sqrt(N)
print(f"効果量 r: {r:.3f}")
まとめ
- ノンパラメトリック検定の選択は「群数(2群 or 多群)」と「対応の有無」の2軸で決まる
- scipy.stats の4関数(
mannwhitneyu/wilcoxon/kruskal/friedmanchisquare)でほぼカバーできる - 多群比較では必ず多重比較(ボンフェローニ補正など)を実施する
- p値だけでなく効果量 r も報告すると、実務的な意義を伝えやすい
Excelでのノンパラメトリック検定の計算手順はウィルコクソンの順位和検定・ クルスカルワリス検定の各記事を参照してください。 どの検定を選ぶかの判断フローは統計的検定の選び方にまとめています。
