
「合否」「正常・異常」「発生・未発生」——現場のデータには、こういう0か1かの判定結果がよく出てきます。ところがこういう2値データに線形回帰をかけようとすると、予測値が1を超えたり0を下回ったりしてしまいます。
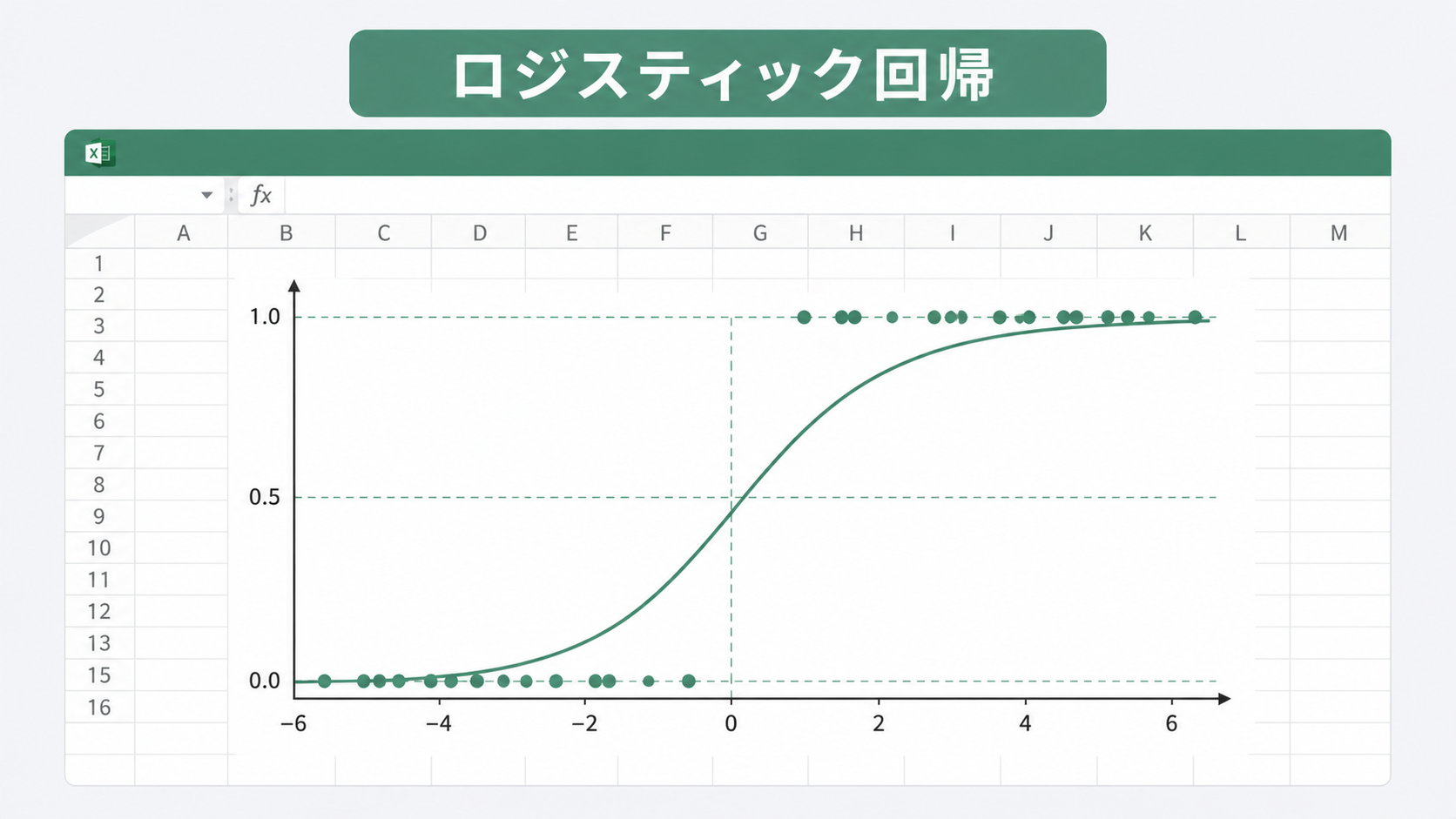
ここで使うのがロジスティック回帰です。シグモイド関数を使って、予測値を必ず0から1の間に収める仕組みになっています。この記事では、引張強度と脆性破壊の例題を使って、ロジスティック回帰の原理・係数の推定手順・Excelソルバーでの実装・オッズ比による解釈まで順に説明します。
線形回帰との違い
目的変数(y)が連続値であれば線形回帰が使えます。y = β₀ + β₁x という式で予測値を計算するだけです。
ところがyが0か1しかとらない場合、予測値が1を超えたり0を下回ることが普通に起きます。「割れが発生する確率が120%」という値は意味をなしません。ロジスティック回帰では、線形回帰の予測値をシグモイド関数に通すことでこの問題を解決します。予測値は必ず0から1の間に収まり、「確率」として解釈できます。
ロジスティック関数(シグモイド関数)
ロジスティック回帰で使うシグモイド関数は次の式です。\[ p = \frac{1}{1 + e^{-z}}, \quad z = \beta_0 + \beta_1 x \]
zが大きくなれば p は1に近づき、zが小さくなれば p は0に近づきます。zが0のとき p = 0.5 です。このS字のカーブがロジスティック回帰の特徴で、「イベントが起こる確率」として自然に解釈できます。
線形回帰と比べると、予測の式は似ていますが、出力が確率に変換されている点が根本的に違います。
| 項目 | 線形回帰 | ロジスティック回帰 |
|---|---|---|
| 目的変数 | 連続値(−∞ ~ +∞) | 2値(0 または 1) |
| 予測値の範囲 | −∞ ~ +∞ | 0 ~ 1(確率) |
| 変換関数 | なし | シグモイド関数 |
| 推定方法 | 最小二乗法 | 最尤法 |
例題の設定
電子機器部品の耐衝撃試験を例題に使います。引張強度(MPa)を変えながら10個のサンプルを製造し、衝撃試験で脆性破壊が発生したかどうかを記録しました。
| No. | 引張強度 x (MPa) | 脆性破壊 y(0:なし, 1:あり) |
|---|---|---|
| 1 | 320 | 0 |
| 2 | 330 | 0 |
| 3 | 335 | 1 |
| 4 | 340 | 0 |
| 5 | 345 | 1 |
| 6 | 350 | 0 |
| 7 | 355 | 1 |
| 8 | 360 | 1 |
| 9 | 370 | 1 |
| 10 | 380 | 1 |
引張強度が高いほど脆性破壊が起きやすいという直感に合ったデータです。ただし340〜355 MPaのあたりは0と1が混在していて、完全には分離していません。
最尤法の考え方
線形回帰では係数を「残差二乗和を最小化」して求めますが、ロジスティック回帰では最尤法(Maximum Likelihood Estimation)を使います。
考え方はシンプルです。「いま手元にあるデータが出現する確率を最大にするβ₀とβ₁を選ぶ」というものです。各観測値について、
- y = 1 のとき → 予測確率 p̂ が高いほど良い
- y = 0 のとき → 予測確率 p̂ が低いほど(1−p̂ が高いほど)良い
これを全観測値にわたって掛け合わせたものが尤度(ゆうど)L です。計算しやすいよう対数をとった対数尤度 LL を使います。\[ LL = \sum_{i=1}^{n} \left[ y_i \ln \hat{p}_i + (1 – y_i) \ln(1 – \hat{p}_i) \right] \]
この LL を最大にする β₀ と β₁ を求めるのがロジスティック回帰の推定です。解析的な公式はなく、数値的な反復計算で求めます。
Excelソルバーで係数を推定する
ExcelのソルバーアドインでLLを最大化することで、β₀とβ₁を求められます。
STEP 1:データを入力する
A列に引張強度(x)、B列に破壊有無(y)を入力します。別のセル(例: E1)にβ₀の初期値 0 を、E2にβ₁の初期値 0 を入れておきます。
STEP 2:予測確率 p̂ を計算する
C2セルに以下の式を入力し、C11まで下にコピーします。
=1/(1+EXP(-($E$1+$E$2*A2)))β₀とβ₁のセルは絶対参照($E$1, $E$2)にしておくことがポイントです。
STEP 3:対数尤度の寄与を計算する
D2セルに各観測値の対数尤度を入力します。
=B2*LN(C2)+(1-B2)*LN(1-C2)y=1のとき LN(p̂)、y=0のとき LN(1-p̂) が計算されます。
STEP 4:対数尤度の合計セルを作る
E3セルに =SUM(D2:D11) と入力します。このセルの値をソルバーで最大化します。
STEP 5:ソルバーを実行する
- 「データ」タブ → 「ソルバー」をクリック(ない場合は「ファイル → オプション → アドイン」からソルバーを有効化)
- 目的セル:E3(対数尤度の合計)
- 目標値:「最大値」を選択
- 変数セル:E1:E2(β₀とβ₁)
- 「解決」をクリック
収束すると、β₀ ≈ −42.37、β₁ ≈ 0.1239 が得られます。
STEP 6:予測確率を確認する
推定結果を使って各サンプルの予測確率を計算すると次のようになります。
| No. | 引張強度 x | z = β₀ + β₁x | 予測確率 p̂ | 実測 y |
|---|---|---|---|---|
| 1 | 320 | -2.72 | 0.062 | 0 |
| 2 | 330 | -1.48 | 0.185 | 0 |
| 3 | 335 | -0.86 | 0.297 | 1 |
| 4 | 340 | -0.24 | 0.440 | 0 |
| 5 | 345 | 0.38 | 0.593 | 1 |
| 6 | 350 | 1.00 | 0.731 | 0 |
| 7 | 355 | 1.62 | 0.834 | 1 |
| 8 | 360 | 2.24 | 0.903 | 1 |
| 9 | 370 | 3.48 | 0.970 | 1 |
| 10 | 380 | 4.71 | 0.991 | 1 |
345 MPaで予測確率が59.3%と50%を超え、実際にy=1(破壊あり)でした。340 MPaでは40.4%でy=0(破壊なし)——この付近が「境目」になっていることがデータと一致しています。
係数の解釈:オッズ比
β₁ = 0.1239 という数字が何を意味するかを理解するには、オッズ比を使います。
オッズとは「イベントが起こる確率」を「起こらない確率」で割ったものです。\[ \text{オッズ} = \frac{p}{1-p} \]
ロジスティック回帰のモデルを変形すると、xが1単位増えるとオッズが exp(β₁) 倍になることがわかります。\[ \text{オッズ比} = e^{\beta_1} = e^{0.1239} \approx 1.132 \]
つまり引張強度が1 MPa上昇するたびに、脆性破壊のオッズが1.132倍(約13.2%増)になります。「引張強度が高いほど破壊しやすい」という直感を数値で表せました。
50%確率になる強度
破壊確率がちょうど50%になる強度(しきい値)は、z = 0 となるxを求めれば出ます。\[ 0 = \beta_0 + \beta_1 x \implies x = -\frac{\beta_0}{\beta_1} = -\frac{-42.37}{0.1239} \approx 342 \text{ MPa} \]
342 MPaが「半々の境目」です。この値は製造仕様を決めるときの参考になります。安全マージンを考慮して、例えば320 MPa以下を目標強度に設定する、といった使い方ができます。
モデルの評価
推定できたモデルがどれくらい当てはまっているかを確認する指標です。
McFadden R²(疑似決定係数)
線形回帰の R² に相当する指標ですが、計算式が違います。\[ R^2_{\text{McFadden}} = 1 – \frac{LL_{\text{model}}}{LL_{\text{null}}} \]
ここで LL_null は切片(β₀)だけのモデルの対数尤度です。今回の例題では LL = −4.22、LL_null = −6.73 なので、\[ R^2_{\text{McFadden}} = 1 – \frac{-4.22}{-6.73} = 0.37 \]
0.2〜0.4が「良好なあてはまり」の目安とされています。今回は 0.37 なので、モデルとデータの対応は十分です。
AIC(赤池情報量基準)
パラメータ数(ここでは2)を考慮したモデル選択の指標です。\[ \text{AIC} = -2 \times LL + 2k = -2 \times (-4.22) + 2 \times 2 = 12.43 \]
AICは値が小さいほど良いモデルとされています。複数の説明変数を試した場合の比較に使います。
混同行列(参考)
予測確率が0.5以上を「破壊あり」、0.5未満を「破壊なし」と予測したとき、実測との一致率を見ます。今回のデータでは10件中8件が正しく予測できています(正解率80%)。なお、混同行列の詳しい見方はサンプルサイズが大きいケースで特に有効です。
まとめ
- ロジスティック回帰は、目的変数が0/1の2値データに使う回帰手法
- シグモイド関数により予測値が0〜1の確率として出力される
- 係数は最尤法で推定し、Excelソルバーで求められる(β₀ ≈ −42.37、β₁ ≈ 0.124)
- exp(β₁) = オッズ比で、説明変数の1単位増加がイベント確率に与える影響を解釈できる
- −β₀/β₁ で予測確率50%になる閾値を求められる(今回は342 MPa)
ロジスティック回帰は「合否判定」「不良発生の予測」など、製造現場で使いやすい手法です。線形回帰と原理が似ていて、Excelソルバーで実装できるのも強みです。説明変数が複数ある場合(重ロジスティック回帰)に拡張するときも、基本の考え方は変わりません。
回帰分析の前提確認や残差の見方については、回帰分析の前提条件と残差分析も合わせて参考にしてください。通常の回帰と比較しながら読むと、ロジスティック回帰の特徴がより明確になります。また、目的変数が連続値の場合の回帰については回帰分析のやり方と結果の見方、複数の説明変数を使う場合は重回帰分析の結果の読み方と変数選択をご覧ください。
説明変数が多変量で正規分布に近い場合は、線形判別分析(LDA)も2値分類の選択肢になります。ロジスティック回帰が確率モデルを推定するのに対し、LDAはグループ間距離を直接最大化するアプローチです。

