
一元配置分散分析でp値が0.05を下回っても、それだけでは「どのグループとどのグループに差があるか」はわかりません。3グループあれば比較の組み合わせはA-B、B-C、A-Cの3通り。そこを調べるのが多重比較法で、TukeyのHSD法はその中で最もよく使われる手法のひとつです。
TukeyのHSD法とは
HSDは「Honestly Significant Difference(正直な有意差)」の略です。全ペアの比較を同時に行い、第一種の過誤(本来は差がないのに差があると誤判定する確率)を指定した水準以下に抑えます。
特徴を一言で言うと、各グループのサンプルサイズが等しいとき最も検出力が高い手法です。サンプルサイズが異なる場合はTukey-Kramer法(Excelでも自動対応)で調整します。多重比較法の選び方も合わせて確認しておくと判断がしやすくなります。
計算の仕組み
TukeyのHSD法では、各ペアの平均差とHSD値(判定基準)を比較します。\[ HSD = q_{\alpha}(k, \phi_E) \times \sqrt{\frac{V_E}{n}} \]
- \(q_{\alpha}(k, \phi_E)\):スチューデント化された範囲の分位点(q表から引く)
- \(V_E\):誤差分散(分散分析表の「グループ内」の分散)
- \(n\):各グループのサンプルサイズ
- \(k\):グループ数
- \(\phi_E\):誤差の自由度
各ペアの平均差の絶対値がHSDを超えれば、そのペアに有意差ありと判定します。\[ |\bar{x}_i – \bar{x}_j| > HSD \Rightarrow \text{有意差あり} \]
具体例:3条件の製品強度を多重比較する
一元配置分散分析を例題で解説の記事で使った例題の続きです。処理条件A・B・Cで製品強度(MPa)を4回ずつ計測し、分散分析の結果「3条件の間に有意差あり(p = 0.008)」が出ました。
| 条件A | 条件B | 条件C | |
|---|---|---|---|
| 平均値 | 52.5 MPa | 61.0 MPa | 57.5 MPa |
| サンプルサイズ n | 4 | 4 | 4 |
分散分析表から得られた値:
- 誤差分散 \(V_E = 6.67\)
- 誤差の自由度 \(\phi_E = 9\)
Step 1:HSD値を計算する
グループ数 \(k = 3\)、誤差の自由度 \(\phi_E = 9\)、有意水準5%のq値はスチューデント化範囲表から \(q_{0.05}(3, 9) = 3.95\) です。\[ HSD = 3.95 \times \sqrt{\frac{6.67}{4}} = 3.95 \times \sqrt{1.67} = 3.95 \times 1.29 \approx 5.11 \]
Step 2:全ペアの平均差を計算する
| 比較ペア | 平均差 \(|\bar{x}_i – \bar{x}_j|\) | HSD(5.74)との比較 | 判定 |
|---|---|---|---|
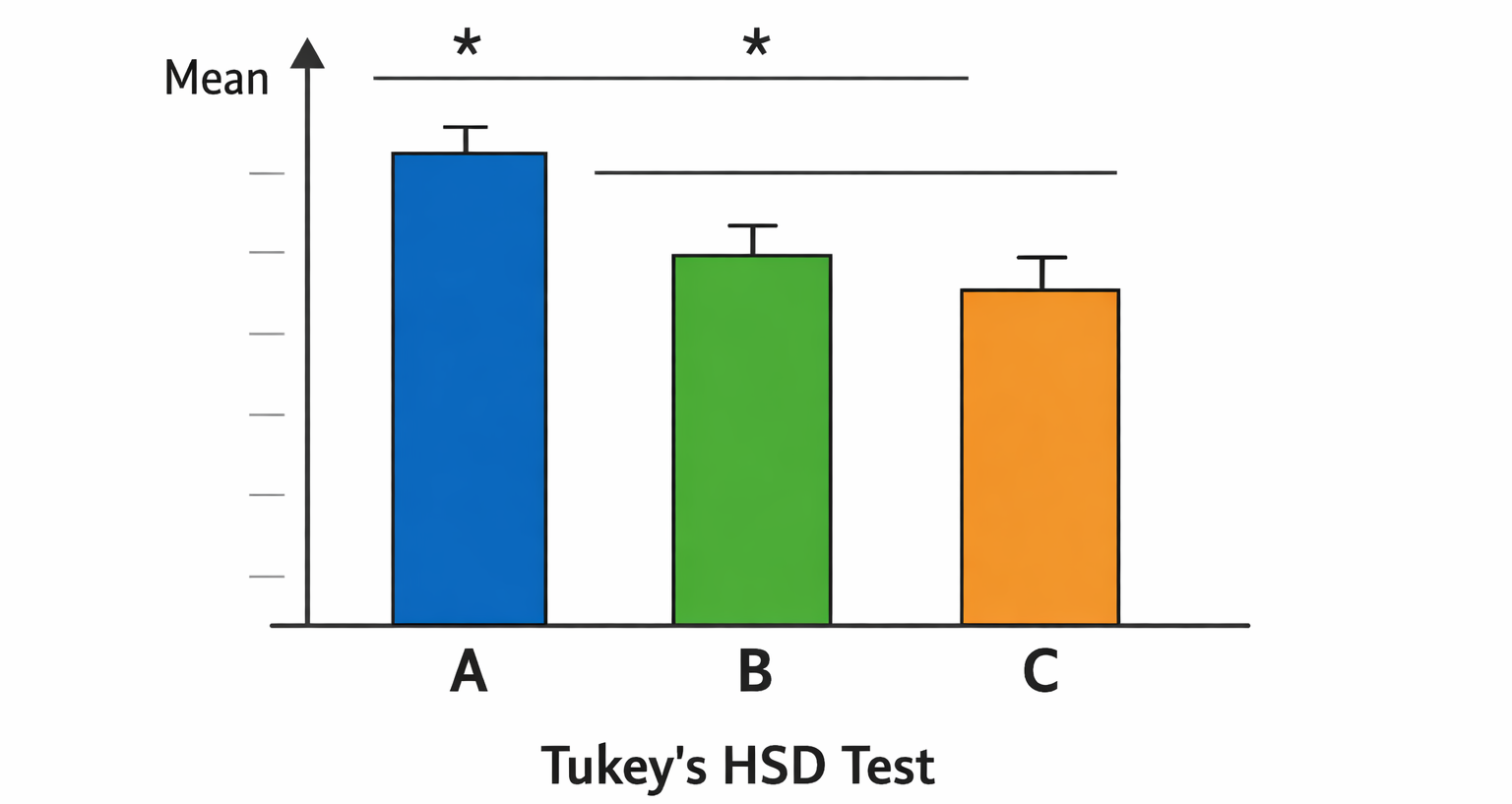
| A vs B | |52.5 − 61.0| = 8.5 | 8.5 > 5.11 | 有意差あり * |
| A vs C | |52.5 − 57.5| = 5.0 | 5.0 < 5.11 | 有意差なし |
| B vs C | |61.0 − 57.5| = 3.5 | 3.5 < 5.11 | 有意差なし |
条件AとBの間にのみ有意差があることがわかりました。条件Bが最も強度が高く、条件Aとは統計的に区別できる差があります。条件Cはどちらとも有意差がない、中間的な位置づけです。
ボンフェローニ法・ホルム法との違い
多重比較法にはいくつか種類があります。TukeyのHSD法との主な違いはこちらです。
| 手法 | 特徴 | 向いている場面 |
|---|---|---|
| TukeyのHSD法 | 全ペア比較向け。等サンプルサイズで最も検出力が高い | 全条件を網羅的に比較したいとき |
| ボンフェローニ法 | 計算がシンプル。やや保守的(差を検出しにくい) | 比較ペアが少ないとき、または比較対象が決まっているとき |
| ホルム法 | ボンフェローニより検出力が高い。ペア数が多いときに有利 | 比較ペアが多く、できるだけ差を見逃したくないとき |
実務では「とりあえず全ペア比較したい」ならTukey、「あらかじめ気になるペアが決まっている」ならボンフェローニかホルム、という使い分けが多いです。
ExcelでTukeyのHSD法を計算する
ExcelにはTukeyのHSD法の専用ツールは用意されていません。ただし、次の手順で対応できます。
- Excelの分散分析ツールで \(V_E\) と \(\phi_E\) を取得する
- q値をスチューデント化範囲表(または
=QINV(0.05, k, φ_E)関数)から求める - HSD値を計算し、各ペアの平均差と比較する
Pythonを使う場合は statsmodels の pairwise_tukeyhsd() 関数で一発です。Pythonで分散分析の記事内でも触れています。
まとめ
TukeyのHSD法で確認できることは「どのペアに有意差があるか」です。分散分析で有意差が出たら、必ずセットで使うようにしてください。
計算の流れは、分散分析表から \(V_E\) と \(\phi_E\) を取り出し、q表からHSD値を求め、全ペアの平均差と比較するだけです。手順自体は単純なので、一度やってみると感覚が掴めます。
なお、TukeyのHSD法は「全ペアを比較する」前提の手法です。「対照群との比較だけでいい」という場面ではDunnett法の方が検出力が高くなります。用途に合わせて選んでください。
