回帰分析の結果を報告したとき、「この分析、前提条件は確認しましたか?」と聞かれて困った経験はないでしょうか。R²が高くても、前提条件が満たされていなければ予測値や係数の信頼性は保証されません。
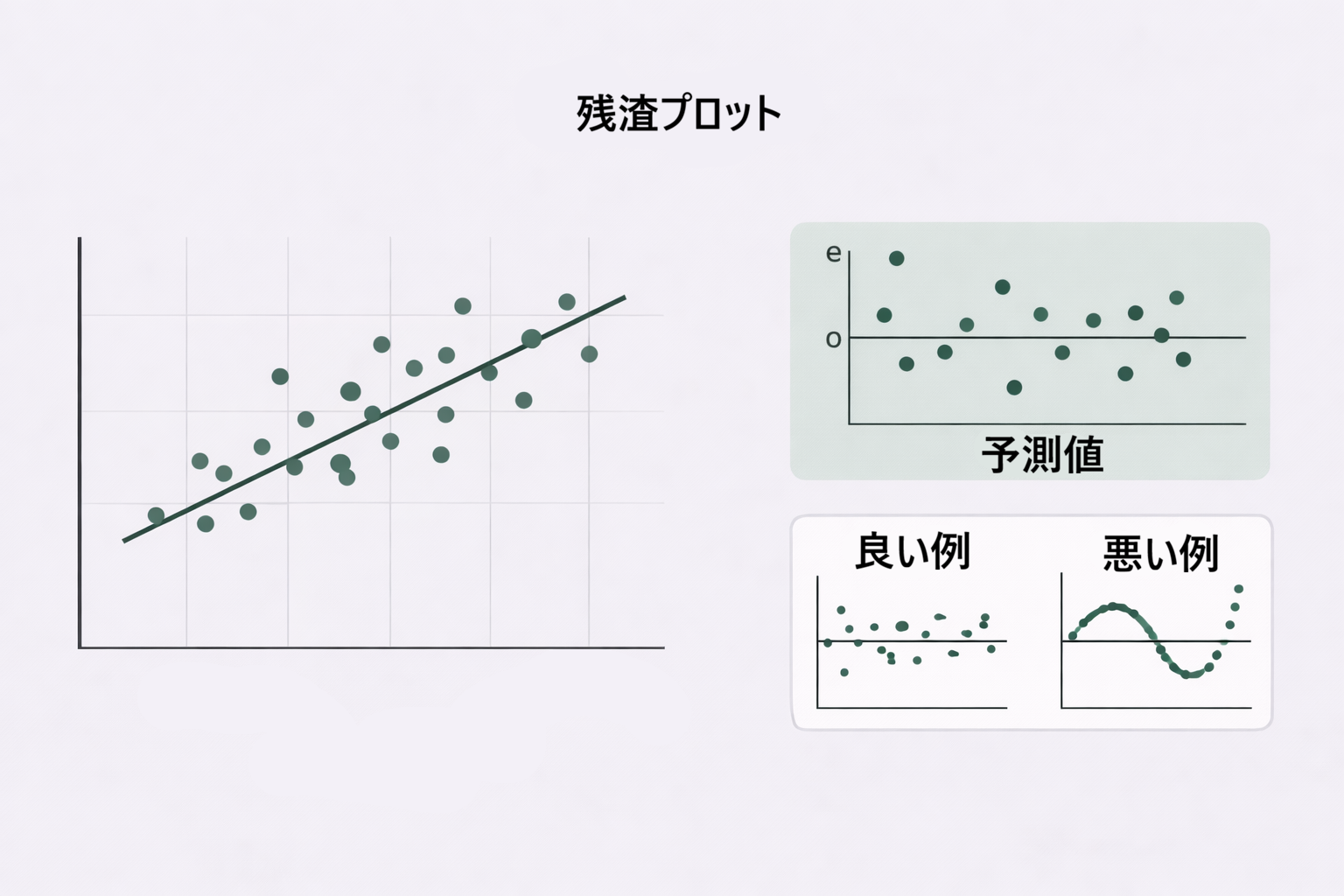
回帰分析には使用前に確認すべき4つの前提条件があります。これを確認する作業が残差分析です。残差(実測値と予測値の差)の振る舞いを見ることで、回帰モデルがデータに適切に当てはまっているかどうかを判断します。
この記事では、4つの前提条件の意味とその確認方法を、Excel手順とPythonコードを使って一通り解説します。例題として、射出成形の金型温度と製品収率のデータ(n=15)を使います。
回帰分析の4つの前提条件
単回帰・重回帰分析を正しく使うには、以下の4条件が必要です。
| 条件 | 意味 | 確認方法 |
|---|---|---|
| ① 線形性 | 説明変数と目的変数の関係が直線で近似できる | 残差プロット(予測値 vs 残差) |
| ② 残差の正規性 | 残差が正規分布に従っている | ヒストグラム・Q-Qプロット・シャピロウイルク検定 |
| ③ 等分散性 | 残差のばらつきが予測値によらず一定 | 残差プロット(扇形の広がりがないか確認) |
| ④ 独立性 | 残差同士に系列相関がない | ダービン・ワトソン統計量 |
4つのうち、①と③は同じ「残差プロット」で同時に確認できます。まず残差プロットを作り、その後で②③を追加で検討するのが実務での流れです。
例題:射出成形の温度と収率
金型温度(°C)を変えたときの製品収率(%)を15回測定したデータを使います。
| No. | 温度(°C) | 収率(%) | No. | 温度(°C) | 収率(%) |
|---|---|---|---|---|---|
| 1 | 160 | 72.1 | 9 | 200 | 82.4 |
| 2 | 165 | 73.8 | 10 | 205 | 83.1 |
| 3 | 170 | 75.2 | 11 | 210 | 84.9 |
| 4 | 175 | 76.4 | 12 | 215 | 85.7 |
| 5 | 180 | 78.0 | 13 | 220 | 86.3 |
| 6 | 185 | 78.9 | 14 | 225 | 87.5 |
| 7 | 190 | 80.1 | 15 | 230 | 88.2 |
| 8 | 195 | 81.5 |
回帰分析の基本手順(Excelのデータ分析ツールを使った係数の求め方)は回帰分析のやり方と結果の見方でまとめています。ここでは前提条件の確認に絞って説明します。
Excelで残差を出力する手順
「データ分析」ツールの回帰分析を実行するとき、残差の出力オプションにチェックを入れます。
ステップ1:回帰分析を実行して残差を出力する
- 「データ」タブ → 「データ分析」→ 「回帰分析」を選択
- 入力 Y 範囲:収率データ(C列)
- 入力 X 範囲:温度データ(B列)
- 「残差」にチェック
- 「残差グラフ」にチェック
- 「OK」をクリック
出力シートに「残差出力」テーブルが生成されます。「予測値」と「残差」の列が追加されているので、この2列を使ってグラフを作ります。
ステップ2:残差プロットを作る
横軸に予測値、縦軸に残差を取った散布図を作ります。Excelが自動生成する「残差グラフ」は横軸が説明変数(温度)なので、横軸を「予測値」に変えるひと手間が必要です。
- 残差出力の「予測値」列と「残差」列を選択
- 「挿入」→ 「散布図」を選択
- グラフタイトルを「残差プロット(予測値 vs 残差)」に変更
- y = 0 の水平線を追加(「グラフ要素」→「誤差範囲」または手動で参照線を追加)
残差プロットの読み方
残差プロットは以下のパターンで判断します。
| 残差の見え方 | 判断 | 対応 |
|---|---|---|
| ランダムに散らばっている(パターンなし) | 線形性・等分散性OK | そのまま使用可能 |
| U字型・逆U字型のカーブがある | 線形性に問題あり | 二乗項の追加・変数変換を検討 |
| 予測値が大きくなるほど残差のばらつきが広がる(扇形) | 等分散性に問題あり | 目的変数の対数変換などを検討 |
| 残差が上下に交互に並ぶ(系列パターン) | 独立性に問題あり | 時系列データの場合、自己回帰モデルを検討 |
今回の例題では残差がランダムに散らばっており、線形性・等分散性はOKと判断できます。
残差の正規性を確認する
残差のヒストグラムと Q-Q プロット、必要に応じてシャピロウイルク検定で確認します。
Excelでのヒストグラム作成
残差の列をコピーして別シートに貼り付け、ヒストグラムを作るやり方の手順でヒストグラムを作ります。山が左右対称で釣り鐘型に近ければ正規分布に近いと判断できます。
Q-Qプロットと検定
ヒストグラムだけでは判断が難しい場合は、Q-Qプロットやシャピロウイルク検定を使います。残差データへの適用手順はExcelで正規性を確認する方法と同じです。残差の列を測定データの代わりに使えばそのまま応用できます。
シャピロウイルク検定で p 値 > 0.05 であれば、正規分布を棄却する根拠なし(正規性OK)と判断します。
Pythonで残差分析をまとめて行う
statsmodels を使うと、回帰分析と残差分析を一気にできます。
モデルの構築と残差の取得
import numpy as np
import pandas as pd
import statsmodels.api as sm
from scipy import stats
import matplotlib.pyplot as plt
from statsmodels.stats.stattools import durbin_watson
# データ
temperature = np.array([160,165,170,175,180,185,190,195,200,205,210,215,220,225,230])
yield_rate = np.array([72.1,73.8,75.2,76.4,78.0,78.9,80.1,81.5,82.4,83.1,84.9,85.7,86.3,87.5,88.2])
# 回帰モデル
X = sm.add_constant(temperature)
model = sm.OLS(yield_rate, X).fit()
print(model.summary())
# 残差・予測値
residuals = model.resid
fitted = model.fittedvalues
① 残差プロット(線形性・等分散性)
plt.figure(figsize=(8, 5))
plt.scatter(fitted, residuals, color='steelblue')
plt.axhline(y=0, color='red', linestyle='--')
plt.xlabel('予測値')
plt.ylabel('残差')
plt.title('残差プロット(予測値 vs 残差)')
plt.tight_layout()
plt.show()
② 残差の正規性(シャピロウイルク検定)
stat, p_value = stats.shapiro(residuals)
print(f'シャピロウイルク検定: W={stat:.4f}, p={p_value:.4f}')
if p_value > 0.05:
print('→ 正規性を棄却する根拠なし(p > 0.05)')
else:
print('→ 正規分布に従わない可能性あり(p ≤ 0.05)')
③ 独立性(ダービン・ワトソン統計量)
dw = durbin_watson(residuals)
print(f'ダービン・ワトソン統計量: {dw:.4f}')
# 目安:2.0に近いほど独立性OK
# 0に近い → 正の自己相関あり
# 4に近い → 負の自己相関あり
今回の例題での結果:
- 残差プロット:ランダムな分布(線形性・等分散性OK)
- シャピロウイルク:p ≈ 0.68(正規性OK)
- ダービン・ワトソン:約 2.1(独立性OK)
4つの前提条件がすべて満たされていることが確認でき、この回帰モデルは信頼できると判断できます。
前提条件が満たされない場合の対処
線形性が成立しない場合
残差プロットにU字型のカーブが見られる場合、説明変数の二乗項を追加します(多項式回帰)。または目的変数・説明変数の対数変換や平方根変換を試します。
等分散性が成立しない(分散不均一)場合
目的変数を対数変換すると改善することが多い。また重み付き最小二乗法(WLS)も選択肢です。等分散性の検定はルビーン検定で等分散性を確認するでまとめています。
正規性が成立しない場合
サンプルサイズが大きい(n ≥ 30)場合は中心極限定理により係数推定への影響は小さくなります。小サンプルで正規性が崩れる場合は、ロバスト回帰やブートストラップ法を検討します。
独立性が成立しない(自己相関あり)場合
時系列データに多い問題です。ダービン・ワトソン統計量が 1.5 未満または 2.5 超の場合は自己回帰モデル(AR)や差分変換を検討します。
残差分析の流れをまとめると
実務では以下の順で確認すると効率的です。
- 残差プロットを作る(線形性・等分散性を同時確認)
- パターンがなければ ヒストグラム・Q-Qプロット で正規性を目視確認
- 必要ならシャピロウイルク検定で定量的に確認(n ≤ 50 のときに特に有効)
- 時系列データなら ダービン・ワトソン統計量 で独立性も確認
- 問題が見つかったら変数変換やモデル修正を検討
残差プロットで「ランダムに散らばっている」ことが確認できれば、多くの場合は安心して結果を使えます。残差分析に慣れてくると、モデルの問題点が視覚的に読み取れるようになります。
まとめ
- 回帰分析の前提条件は「線形性・正規性・等分散性・独立性」の4つ
- 残差プロット(予測値 vs 残差)でまず線形性と等分散性を確認する
- 残差のヒストグラム・Q-Qプロット・シャピロウイルク検定で正規性を確認する
- 時系列データはダービン・ワトソン統計量で独立性も確認する
- Excelはデータ分析ツールの「残差出力」チェックで残差を取得できる
- Pythonの statsmodels を使えば残差取得と各検定をまとめて実行できる
回帰分析自体の手順は回帰分析のやり方と結果の見方で、統計検定全体の使い分けは統計的検定の選び方(フロー図付き)でまとめています。合わせて参考にしてください。