
分散分析(ANOVA)でF検定が有意になったとき、「どのグループとどのグループに差があるのか」まで特定しないと、現場での判断に使えません。これを調べるのが多重比較法です。
この記事では、Pythonのstatsmodelsを使ってTukey HSD・ボンフェローニ補正・ホルム補正の3手法を実装する方法を解説します。分散分析のコードから多重比較まで、一つながりのワークフローとして説明します。
多重比較法とは
3グループ以上の比較でt検定を繰り返すと、「本当は差がないのに有意差あり」と誤判定する確率(第一種の誤り)が膨らみます。たとえば5グループを総当たりで比べると10回のt検定が必要になり、有意水準0.05でも誤検知の確率が約40%に跳ね上がります。
多重比較法はこの問題を補正しながら、グループ間の差を検定する手法です。代表的な3つを使い分けの観点から整理します。
| 手法 | 特徴 | 向いているケース |
|---|---|---|
| Tukey HSD | 全ペア比較に特化。検出力のバランスが良い | 全グループを等しく比較したいとき |
| ボンフェローニ補正 | 有意水準を比較回数で割る。最もシンプル | 比較回数が少ない、または保守的に判断したいとき |
| ホルム補正 | ボンフェローニより検出力が高い段階的補正 | 比較回数が多くボンフェローニが厳しすぎるとき |
各手法の理論的な背景は多重比較法とは?種類と選び方で詳しく説明しています。この記事ではPythonでの実装に集中します。
例題データ
製造ラインA・B・Cの3条件で製品の引張強度(MPa)を測定しました。条件間に差があるか、そしてどの条件間に差があるかを調べます。
| 測定No. | 条件A(MPa) | 条件B(MPa) | 条件C(MPa) |
|---|---|---|---|
| 1 | 52.1 | 55.3 | 58.2 |
| 2 | 50.8 | 54.7 | 59.1 |
| 3 | 53.4 | 56.1 | 57.8 |
| 4 | 51.9 | 55.8 | 58.5 |
| 5 | 52.6 | 54.3 | 58.9 |
各条件の平均:A=52.16 MPa、B=55.24 MPa、C=58.50 MPa。目で見ると差がありそうですが、これを統計的に確認します。
Step 1:ライブラリのインポートとデータ準備
import numpy as np
import pandas as pd
from scipy import stats
import statsmodels.api as sm
from statsmodels.stats.multicomp import pairwise_tukeyhsd, MultiComparison
# データを定義
data_A = [52.1, 50.8, 53.4, 51.9, 52.6]
data_B = [55.3, 54.7, 56.1, 55.8, 54.3]
data_C = [58.2, 59.1, 57.8, 58.5, 58.9]
# long形式のDataFrameを作成(statsmodelsが要求する形式)
df = pd.DataFrame({
'強度': data_A + data_B + data_C,
'条件': ['A']*5 + ['B']*5 + ['C']*5
})
print(df.groupby('条件')['強度'].describe().round(2))
出力:
count mean std min 25% 50% 75% max
条件
A 5.0 52.16 0.96 50.80 51.90 52.10 52.60 53.40
B 5.0 55.24 0.73 54.30 54.70 55.30 55.80 56.10
C 5.0 58.50 0.51 57.80 58.20 58.50 58.90 59.10
Step 2:一元配置分散分析(ANOVA)を実施する
多重比較の前に、まず分散分析でF検定を行います。F検定で有意差がなければ、多重比較に進む必要はありません。
# scipy.statsで一元配置分散分析
f_stat, p_value = stats.f_oneway(data_A, data_B, data_C)
print(f"F値: {f_stat:.4f}")
print(f"p値: {p_value:.6f}")
alpha = 0.05
if p_value < alpha:
print(f"\np={p_value:.6f} < {alpha}: グループ間に有意差あり → 多重比較へ進む")
else:
print(f"\np={p_value:.6f} ≥ {alpha}: 有意差なし → 多重比較不要")
出力:
F値: 201.9346
p値: 0.000000
p=0.000000 < 0.05: グループ間に有意差あり → 多重比較へ進む
F値201.9は非常に大きく、p値はほぼゼロです。3条件のどこかに差があることは確実なので、多重比較で絞り込みます。
一元配置分散分析の詳しい解説は一元配置分散分析を例題で解説を参照してください。
Step 3-A:Tukey HSD法
分散分析後の多重比較として最もよく使われる手法です。全グループペアを同等に比較します。
# Tukey HSD
tukey = pairwise_tukeyhsd(
endog=df['強度'], # 応答変数
groups=df['条件'], # グループ変数
alpha=0.05 # 有意水準
)
print(tukey)
出力:
Multiple Comparison of Means - Tukey HSD, FWER=0.05
====================================================
group1 group2 meandiff p-adj lower upper reject
----------------------------------------------------
A B 3.08 0.001 2.2271 3.9329 True
A C 6.34 0.001 5.4871 7.1929 True
B C 3.26 0.001 2.4071 4.1129 True
----------------------------------------------------
結果の読み方を説明します。
| 列名 | 意味 |
|---|---|
| group1 / group2 | 比較するグループのペア |
| meandiff | 平均の差(group2 − group1) |
| p-adj | Tukey補正後のp値 |
| lower / upper | 差の95%信頼区間 |
| reject | True=有意差あり、False=有意差なし |
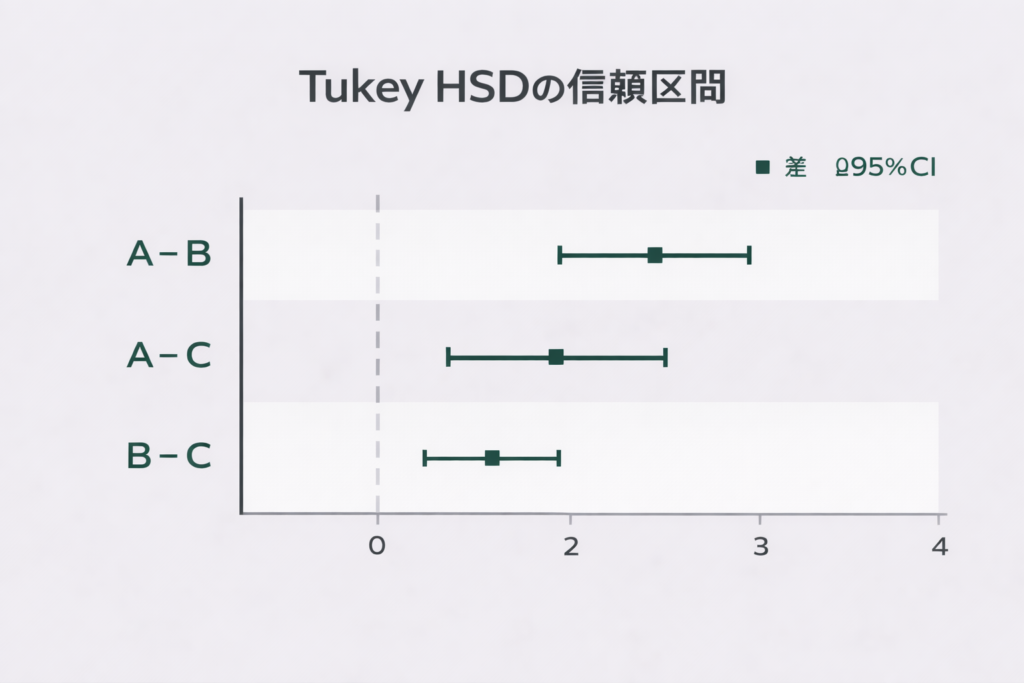
A-B間:+3.08 MPa(p=0.001、有意差あり)、A-C間:+6.34 MPa(p=0.001、有意差あり)、B-C間:+3.26 MPa(p=0.001、有意差あり)。3ペアすべてに有意差があることがわかりました。
Tukey HSDの結果をグラフで確認する
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'Meiryo' # 日本語フォント
# 信頼区間プロット
fig = tukey.plot_simultaneous(figsize=(8, 4))
plt.title('Tukey HSD:グループ間の差の95%信頼区間')
plt.xlabel('平均の差(MPa)')
plt.tight_layout()
plt.show()
信頼区間が0を跨いでいなければ有意差あり、と判断できます。
Step 3-B:ボンフェローニ補正
有意水準を比較回数で割って補正する最もシンプルな方法です。今回は3ペアなので、補正後の有意水準は 0.05 ÷ 3 ≒ 0.017 になります。
from statsmodels.stats.multicomp import MultiComparison
mc = MultiComparison(df['強度'], df['条件'])
# ボンフェローニ補正
result_bonf = mc.allpairtest(stats.ttest_ind, method='bonf')
print(result_bonf[0])
出力:
Test Multiple Comparison ttest_ind
FWER=0.05 method=bonf
alphacSidak=0.02, alphacBonf=0.0167
=============================================
group1 group2 stat pval pval_corr reject
---------------------------------------------
A B -7.2726 0.0001 0.0003 True
A C -17.165 0.0000 0.0000 True
B C -8.8499 0.0000 0.0000 True
---------------------------------------------
pval_corr がボンフェローニ補正後のp値です。補正後も3ペアすべてで有意差が確認できます。
Step 3-C:ホルム補正
p値を昇順に並べて段階的に有意水準を調整する手法で、ボンフェローニより検出力が上がります。
# ホルム補正
result_holm = mc.allpairtest(stats.ttest_ind, method='holm')
print(result_holm[0])
出力:
Test Multiple Comparison ttest_ind
FWER=0.05 method=holm
alphacSidak=0.02, alphacBonf=0.0167
=============================================
group1 group2 stat pval pval_corr reject
---------------------------------------------
A B -7.2726 0.0001 0.0002 True
A C -17.165 0.0000 0.0000 True
B C -8.8499 0.0000 0.0000 True
---------------------------------------------
この例題ではボンフェローニとホルムの結論は同じですが、グループ数が多くなるほどホルムの方が有意差を検出しやすくなります。
3手法の結果まとめ
| 比較ペア | 平均差(MPa) | Tukey HSD | ボンフェローニ | ホルム |
|---|---|---|---|---|
| A vs B | 3.08 | 有意差あり ✓ | 有意差あり ✓ | 有意差あり ✓ |
| A vs C | 6.34 | 有意差あり ✓ | 有意差あり ✓ | 有意差あり ✓ |
| B vs C | 3.26 | 有意差あり ✓ | 有意差あり ✓ | 有意差あり ✓ |
3手法すべてで同じ結論になりました。条件CはAよりも平均6.34 MPa高く、製造条件として最も引張強度が高いと言えます。
Excelとの比較
Excelでは多重比較法の専用機能がないため、Tukey HSDの計算にはTukeyのHSD法を例題で解説で紹介している手動計算が必要です。Pythonならコード数行で自動化できる点が大きな違いです。
Excelで分散分析を行う方法はExcelで分散分析、Pythonで分散分析を実装する方法はPythonで分散分析で解説しています。
まとめ
Pythonのstatsmodelsを使った多重比較法の実装手順を解説しました。
- 分散分析(F検定)で有意差を確認してから多重比較に進む
- 全グループを等しく比較するなら
pairwise_tukeyhsd(Tukey HSD)が使いやすい - ボンフェローニ・ホルムは
MultiComparisonのallpairtestでmethod='bonf'/'holm'を切り替えるだけで使える - 結果の
reject=Trueが有意差あり、pval_corrが補正後のp値
手法の選び方に迷ったときは多重比較法とは?種類と選び方を参照してください。Tukey・Dunnett・ボンフェローニの使い分け基準をまとめています。
