「2グループを比較するとき、まずF検定で等分散かどうか確認してから、その結果に応じてt検定を選ぶ」という手順を聞いたことがある方は多いと思います。ただ、「F検定って何をしてるの?t検定と何が違うの?」が腑に落ちていないまま手順だけ覚えてしまっているケースも少なくありません。この記事でその疑問を整理します。
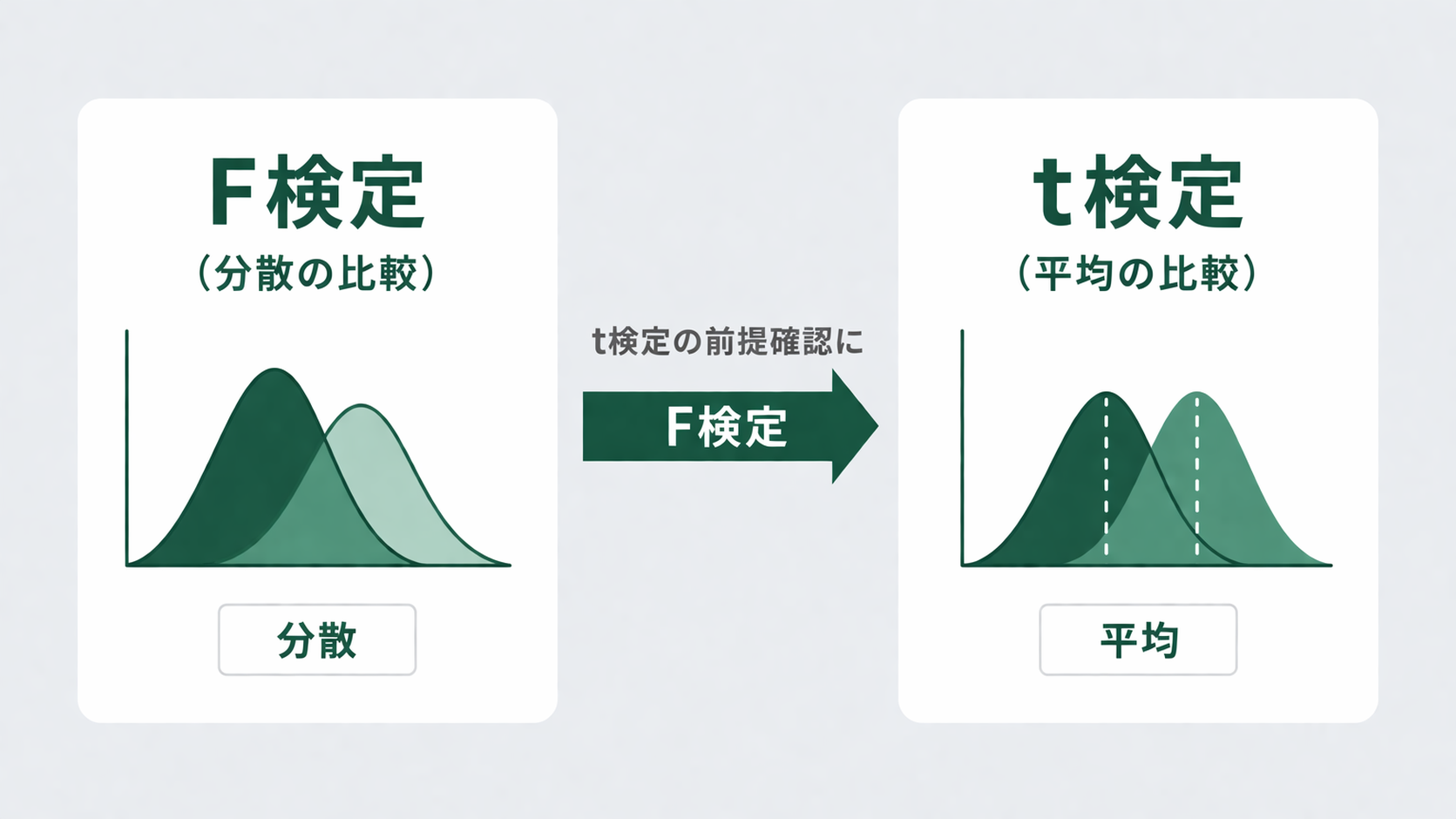
結論から言うと:比べているものが違う
F検定とt検定は、どちらも2グループを比べる検定ですが、何を比べているかがまったく異なります。
- F検定:2グループの分散(ばらつき)が等しいかどうかを調べる
- t検定:2グループの平均値に差があるかどうかを調べる
品質管理の現場で言うと、「ラインAとラインBで製品のばらつき方に違いがあるか」を調べるのがF検定、「ラインAとラインBで製品の平均値に差があるか」を調べるのがt検定です。目的が別なので、どちらか一方を選ぶというわけではありません。
なぜ「t検定の前にF検定」と言われるのか
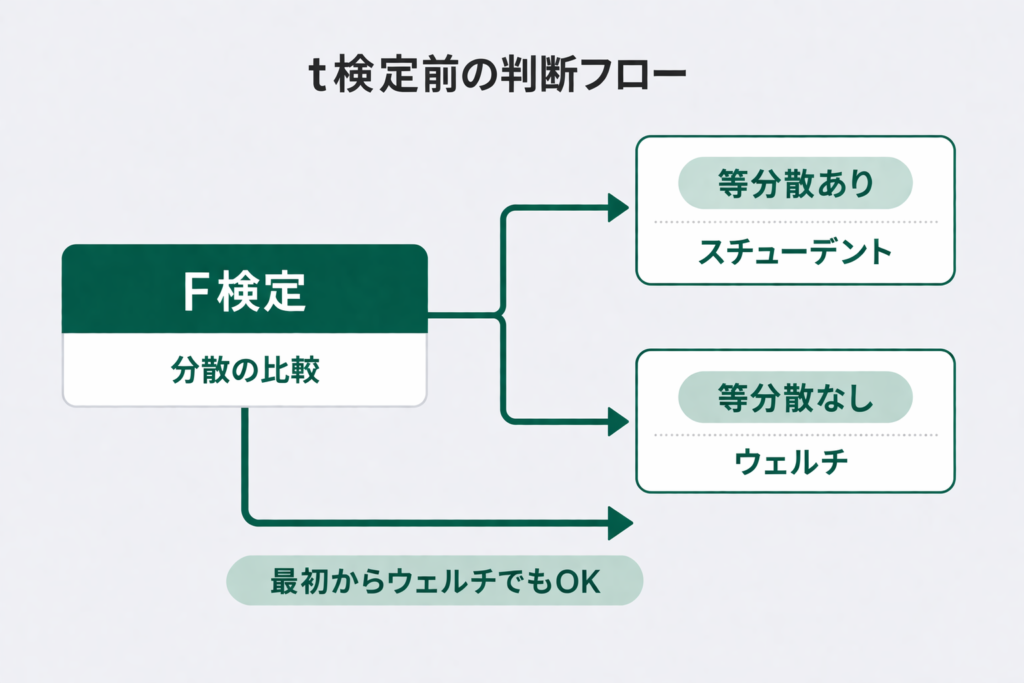
混乱の原因はここにあります。スチューデントのt検定は「2グループの分散が等しい(等分散)」という前提のもとで成立します。この前提が崩れた場合は、等分散を仮定しないウェルチのt検定に切り替える必要があります。
「どちらのt検定を使うか」を判断するために、先にF検定(またはルビーン検定)で等分散かどうかを確認する、という流れが生まれました。Excelの「分析ツール」でも「F検定:2標本を使った分散の検定」と「t検定:2標本による平均の検定」が並んでいるので、セットで使うものという印象を持ちやすいです。
ただし、最初からウェルチのt検定を使う(等分散を仮定しない)方針にすれば、F検定のステップを省略することもできます。スチューデントのt検定はウェルチのt検定の特殊ケースなので、「常にウェルチを使う」というシンプルな運用も実務では多く見られます。
F検定の仕組み:分散の比を使う
F検定の検定統計量はF値と呼ばれ、2つのグループの分散の比で計算します。\[ F = \frac{s_1^2}{s_2^2} \]
\(s_1^2\) と \(s_2^2\) はそれぞれのグループの不偏分散です。分散が等しければ \(F \approx 1\)、大きく異なるほどFが1から離れます。このF値をF分布と照らし合わせてp値を求め、p値が有意水準(通常0.05)を下回れば「等分散でない」と判断します。
具体例:2ラインの硬度データ
製造ラインAとBで製品の硬度(HRC)を各8回測定しました。
| ラインA | ラインB |
|---|---|
| 62 | 60 |
| 63 | 65 |
| 61 | 58 |
| 64 | 67 |
| 62 | 61 |
| 65 | 70 |
| 63 | 59 |
| 61 | 63 |
不偏分散を計算します。
ラインA:平均 \(\bar{x}_A = 62.625\)\[ s_A^2 = \frac{(62-62.625)^2+\cdots+(61-62.625)^2}{7} \approx 1.98 \]
ラインB:平均 \(\bar{x}_B = 62.875\)\[ s_B^2 = \frac{(60-62.875)^2+\cdots+(63-62.875)^2}{7} \approx 16.98 \] \[ F = \frac{s_B^2}{s_A^2} = \frac{16.98}{1.98} \approx 8.57 \]
自由度 (7, 7) のF分布でp値を求めると約0.009。有意水準0.05を下回るので、等分散を棄却します。この場合はウェルチのt検定を使います。
ExcelでF検定とt検定を実行する
F検定の手順
Excelの「分析ツール」を使います。
- データ → データ分析 → 「F検定:2標本を使った分散の検定」を選択
- 「変数1の入力範囲」にラインAのデータを入力
- 「変数2の入力範囲」にラインBのデータを入力
- 有意水準(α)を0.05に設定 → OK
出力に「P(F<=f) 片側」が表示されます。両側検定として判断する場合は、この値を2倍してから0.05と比較します。
また、関数でも計算できます。
=F.TEST(A2:A9, B2:B9) ' 両側p値を返す
t検定の手順(F検定の結果に応じて選択)
F検定でp<0.05(等分散でない)の場合 → 「t検定:分散が等しくないと仮定した2標本による検定」
F検定でp≧0.05(等分散)の場合 → 「t検定:等分散を仮定した2標本による検定」
今回の例はp≒0.009で等分散を棄却したので、ウェルチのt検定(分散が等しくないと仮定)を選びます。
PythonでF検定とt検定を実行する
from scipy import stats
import numpy as np
A = [62, 63, 61, 64, 62, 65, 63, 61]
B = [60, 65, 58, 67, 61, 70, 59, 63]
# F検定(等分散の確認)
f_stat = np.var(B, ddof=1) / np.var(A, ddof=1)
df1 = len(B) - 1
df2 = len(A) - 1
p_f = 2 * min(stats.f.cdf(f_stat, df1, df2),
1 - stats.f.cdf(f_stat, df1, df2))
print(f"F値 = {f_stat:.4f}")
print(f"p値(両側)= {p_f:.4f}")
# t検定(F検定の結果に応じて equal_var を切り替え)
equal_var = p_f >= 0.05 # True: スチューデント / False: ウェルチ
method = "スチューデント" if equal_var else "ウェルチ"
t_stat, p_t = stats.ttest_ind(A, B, equal_var=equal_var)
print(f"\n{method}のt検定")
print(f"t値 = {t_stat:.4f}, p値 = {p_t:.4f}")
出力例:
F値 = 8.5758
p値(両側)= 0.0087
ウェルチのt検定
t値 = -0.1694, p値 = 0.8686
F検定でラインAとBのばらつきに有意な差があると出ました。ウェルチのt検定を実行すると、平均値の差はp=0.87で有意でないという結果です。「ばらつきは違うが、平均はほぼ同じ」というケースです。
「F検定」という言葉が指す3つの異なるもの
少し混乱しやすい点を補足しておきます。「F検定」という言葉は場面によって違うものを指しています。
| F検定の種類 | 目的 | 使う場面 |
|---|---|---|
| 2標本のF検定(分散比の検定) | 2グループの分散が等しいか確認 | t検定の前提確認、製造工程のばらつき比較 |
| 分散分析のF検定 | 3グループ以上の平均に差があるか確認 | 一元配置分散分析・二元配置分散分析 |
| 回帰のF検定 | 回帰モデル全体が有意かどうか確認 | 回帰分析の結果解釈 |
「t検定の前に行うF検定」は1番目の「2標本のF検定」です。分散分析や回帰分析のF検定とは別物なので、混同しないように注意してください。
まとめ
F検定は「ばらつきの比較」、t検定は「平均の比較」。目的が違うので、用途が異なります。「t検定の前にF検定」という手順は、スチューデントかウェルチかを判断するための前提確認として使われます。
ただし、個人的には「常にウェルチのt検定を使う」という方針が実務では扱いやすいと思っています。前提確認のステップが1つ減りますし、等分散が成立している場合でもウェルチのt検定はほぼ同じ結果を出してくれるので、使い分けで迷う必要がなくなります。
どちらのt検定を使うべきかのフローは検定手法の選び方ガイドにまとめてあるので、手法選択全体を整理したい方はそちらも参照してください。