
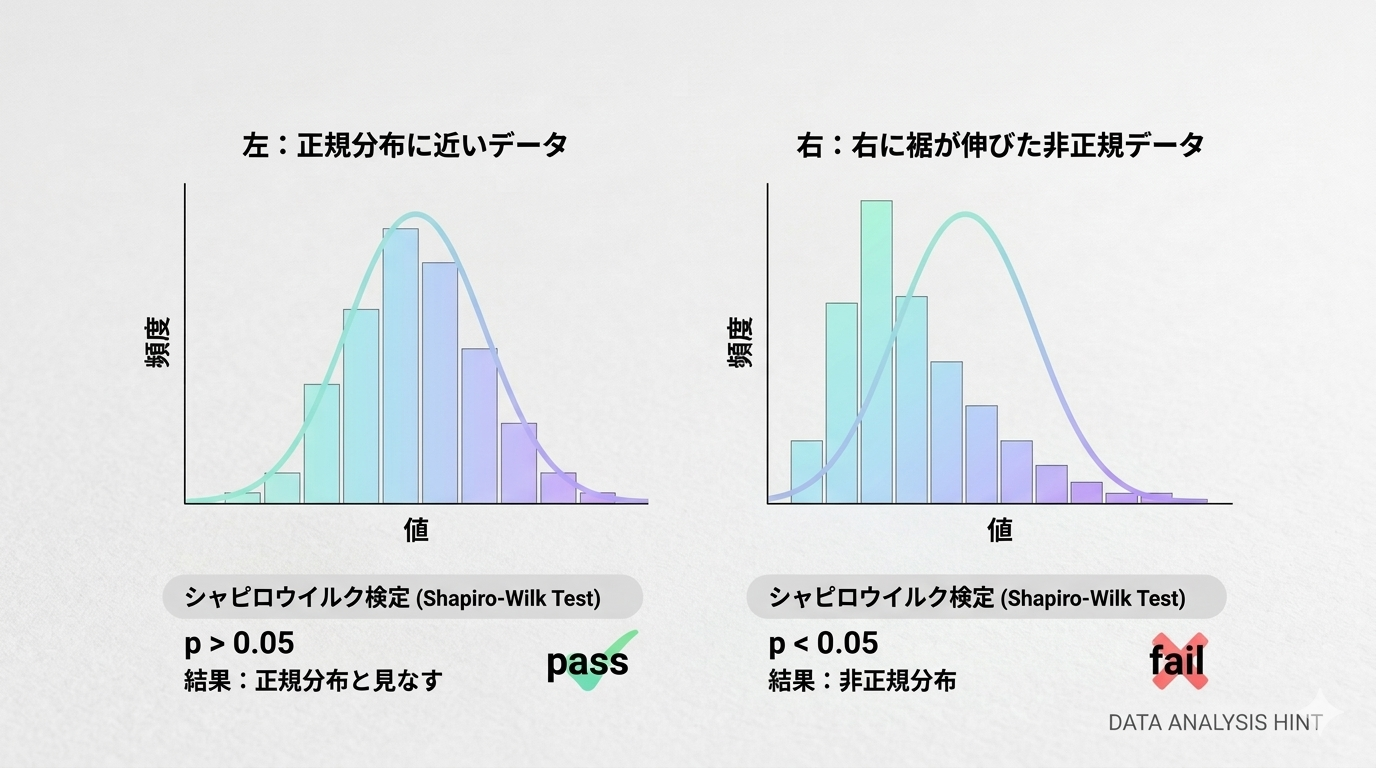
「分散分析を使う前に正規性を確認してください」と言われて、どう確認すればいいか迷ったことはないでしょうか。ヒストグラムを眺めて「まあ正規分布っぽいかな…」と済ませてしまうのは、実は少し危うい。シャピロウイルク検定を使えば、正規性を統計的に判断できます。
なぜ正規性を確認するのか
t検定や一元配置分散分析は、データが正規分布に従っているという前提で成立しています。この前提が崩れると、p値の信頼性が下がります。サンプルサイズが小さいとき(n ≦ 30 程度)は特に影響が出やすいので、前提確認として正規性の検定を行うのが妥当です。
正規性の検定にはいくつかの手法があります。シャピロウイルク検定はそのなかで検出力が高く、特に小〜中サンプル(n ≦ 50)で評判がいい手法です。
シャピロウイルク検定の考え方
帰無仮説は「データは正規分布に従っている」、対立仮説は「正規分布に従っていない」です。
検定統計量 \(W\) は、データを小さい順に並べたとき、「正規分布ならこう並ぶはず」という理論値と実際のデータがどれくらい一致しているかを表します。\[ W = \frac{\left(\sum_{i=1}^{n} a_i x_{(i)}\right)^2}{\sum_{i=1}^{n} (x_i – \bar{x})^2} \]
- \(x_{(i)}\):昇順に並べたデータ(順序統計量)
- \(a_i\):正規分布の期待値から計算される係数(シャピロウイルク係数)
- 分母は通常の分散の分子部分(偏差平方和)
\(W\) は0から1の値を取り、1に近いほど正規分布に近い形をしています。\(W\) が小さすぎる(=p値が有意水準を下回る)と、正規性の仮説を棄却します。
係数 \(a_i\) の計算は手作業では現実的でないので、実務ではPythonやRで計算します。以下では手計算で追える小さなデータ例を使って流れを確認し、その後Pythonでの実装を示します。
具体例:5サンプルのデータで確認する
ある工程で製品の引張強度(MPa)を5回測定しました。
| 測定番号 | 引張強度 \(x_i\) |
|---|---|
| 1 | 52 |
| 2 | 55 |
| 3 | 53 |
| 4 | 49 |
| 5 | 56 |
平均 \(\bar{x} = (52+55+53+49+56)/5 = 53.0\) MPa。
Step 1:昇順に並べる
\(x_{(1)}=49,\ x_{(2)}=52,\ x_{(3)}=53,\ x_{(4)}=55,\ x_{(5)}=56\)
Step 2:係数 \(a_i\) を確認する
\(n=5\) のシャピロウイルク係数表から:
| \(i\) | \(a_i\)(n=5) |
|---|---|
| 1 | 0.5699 |
| 2 | 0.3253 |
| 3 | 0.0000 |
| 4 | −0.3253 |
| 5 | −0.5699 |
\(n=5\) のとき、中央値(\(i=3\))の係数は0です。実際の計算では対称性を利用して、\(i=1,2\) のペアだけ計算します。
Step 3:分子を計算する
\[ \sum a_i x_{(i)} = a_1(x_{(5)}-x_{(1)}) + a_2(x_{(4)}-x_{(2)}) \] \[ = 0.5699 \times (56-49) + 0.3253 \times (55-52) = 0.5699 \times 7 + 0.3253 \times 3 = 3.989 + 0.976 = 4.965 \] 分子の2乗:\(4.965^2 = 24.65\)
Step 4:分母(偏差平方和)を計算する
\[ \sum (x_i – \bar{x})^2 = (52-53)^2+(55-53)^2+(53-53)^2+(49-53)^2+(56-53)^2 = 1+4+0+16+9 = 30 \]
Step 5:W値を計算する
\[ W = \frac{24.65}{30} \approx 0.822 \]
\(n=5\) のシャピロウイルク検定のp値表(有意水準5%)から、\(W=0.822\) に対応するp値はおよそ0.13〜0.15程度。有意水準0.05を下回らないので、正規性の仮説を棄却しない(正規分布と矛盾するデータではない)と判断します。
Pythonでシャピロウイルク検定を実装する
実務では scipy.stats.shapiro() 一行で計算できます。
from scipy import stats
data = [52, 55, 53, 49, 56]
stat, p_value = stats.shapiro(data)
print(f"W = {stat:.4f}")
print(f"p値 = {p_value:.4f}")
if p_value > 0.05:
print("正規性を棄却しない(正規分布と矛盾しない)")
else:
print("正規性を棄却する(正規分布に従っていない可能性がある)")
出力例:
W = 0.9570
p値 = 0.7768
正規性を棄却しない(正規分布と矛盾しない)
手計算と微妙に値が違うのは、Pythonが高精度な係数テーブルを内部で使っているためです。実務ではPythonの値を使ってください。
分散分析の前後でまとめて確認したい場合は、Pythonで分散分析の記事も参考にしてください。各グループごとに stats.shapiro() を呼び出すのが基本的な手順です。
結果の解釈:p値が0.05を下回ったら
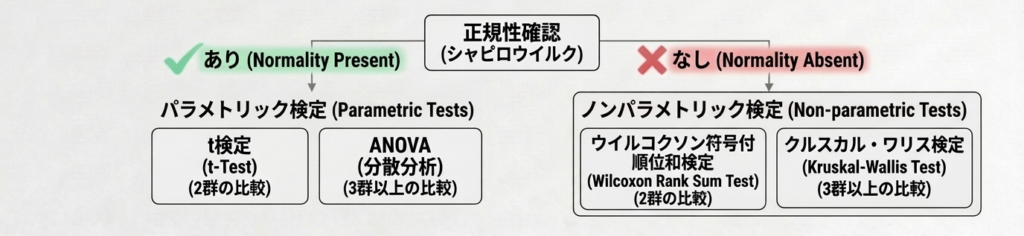
「正規性を棄却しない ≠ 正規分布だと証明した」という点は押さえておく必要があります。検定で棄却されなかったのは、あくまで「正規分布と矛盾するほどの差が見られなかった」というだけです。特にサンプルサイズが小さい場合、検出力も低くなります。
p値が0.05を下回って正規性を棄却した場合、選択肢は主に2つです。
1つ目は、ノンパラメトリック検定に切り替える方法です。t検定の代わりにウイルコクソンの順位和検定、一元配置分散分析の代わりにクルスカルワリス検定が対応する手法になります。
2つ目は、データ変換を試みる方法です。対数変換(log変換)や平方根変換でデータの分布を正規分布に近づけてから検定する場合があります。ただし変換後のデータで出た結果を元のスケールに戻して解釈する手間がかかるので、ノンパラメトリック検定の方が扱いやすいことも多いです。
サンプルサイズと正規性の関係
中心極限定理の効果で、サンプルサイズが大きい(n ≧ 30〜50)場合は、多少の非正規でもt検定や分散分析は比較的ロバストに機能します。逆に言うと、サンプルが大きいほどシャピロウイルク検定は敏感になり、実用上問題のない程度の歪みでもp<0.05になりやすい点には注意してください。
目安として、n ≦ 30 程度のデータでは正規性の確認を実施する価値があります。n が大きい場合はヒストグラムや Q-Q プロットで視覚的に確認する方が実用的なことも多いです。
まとめ
シャピロウイルク検定でやることは、「W値を計算→p値を確認→0.05と比べる」の3ステップです。計算はPythonの scipy.stats.shapiro() に任せてしまえば一行で終わります。
分散分析の前提確認として使うなら、各グループ(条件)ごとに検定するのを忘れずに。一元配置分散分析で3条件を比較するなら、3回 shapiro() を呼び出す形になります。正規性が怪しかったらクルスカルワリス検定に切り替える、という流れで対応できます。
