
t検定を使うとき、「等分散の仮定が必要」と聞いたことがある方は多いと思います。でも実際に等分散かどうかをどう判断するか、ちゃんと確認している現場は意外と少ない。ルビーン検定を使えば、ヒストグラムの目視よりも根拠のある判断ができます。
等分散性とは何か
複数のグループを比較するとき、各グループの母分散が等しいという仮定を「等分散性」と言います。スチューデントのt検定や一元配置分散分析では、この等分散性が前提条件の1つになっています。
前提が崩れた場合の対処法も決まっています。2群比較ならウェルチのt検定(等分散を仮定しない)、多群比較ならウェルチの分散分析に切り替えます。等分散かどうかの判断材料として使う検定が、ルビーン検定です。
ルビーン検定の考え方
帰無仮説は「すべてのグループの分散は等しい」、対立仮説は「少なくとも1つのグループの分散が異なる」です。
ルビーン検定のアイデアは、各グループの「散らばり具合」を数値化してから、その数値をグループ間で比較するというものです。
具体的には、各データ点について「自分のグループ中央値(または平均値)からの絶対偏差」を計算し、その絶対偏差に対して一元配置分散分析を適用します。\[ Z_{ij} = \left| x_{ij} – \tilde{x}_j \right| \]
- \(x_{ij}\):グループ \(j\) の \(i\) 番目のデータ
- \(\tilde{x}_j\):グループ \(j\) の中央値(中央値版ルビーン検定、別名ブラウン-フォーサイス検定)
- \(Z_{ij}\):絶対偏差(散らばりを数値化したもの)
この \(Z_{ij}\) に対して通常の分散分析のF統計量を計算します。グループ間で散らばり具合が同じなら、\(Z_{ij}\) のグループ間差も小さくなりF統計量も小さくなります。逆に等分散でなければF値が大きくなり、p値が有意水準を下回ります。
具体例:3グループの等分散性を確認する
ある工程で3つの製造ラインA・B・Cから各5個のサンプルを採取し、製品の硬度(HRC)を測定しました。
| ラインA | ラインB | ラインC |
|---|---|---|
| 62 | 58 | 65 |
| 63 | 62 | 70 |
| 61 | 60 | 63 |
| 64 | 59 | 72 |
| 62 | 61 | 67 |
Step 1:各グループの中央値を求める
各ラインのデータを昇順に並べて中央値を確認します。
- ラインA:61, 62, 62, 63, 64 → 中央値 \(\tilde{x}_A = 62\)
- ラインB:58, 59, 60, 61, 62 → 中央値 \(\tilde{x}_B = 60\)
- ラインC:63, 65, 67, 70, 72 → 中央値 \(\tilde{x}_C = 67\)
Step 2:絶対偏差 \(Z_{ij}\) を計算する
| ラインA(\(|x – 62|\)) | ラインB(\(|x – 60|\)) | ラインC(\(|x – 67|\)) |
|---|---|---|
| |62−62|=0 | |58−60|=2 | |65−67|=2 |
| |63−62|=1 | |62−60|=2 | |70−67|=3 |
| |61−62|=1 | |60−60|=0 | |63−67|=4 |
| |64−62|=2 | |59−60|=1 | |72−67|=5 |
| |62−62|=0 | |61−60|=1 | |67−67|=0 |
各グループの \(Z_{ij}\) の平均:
- ラインA:\(\bar{Z}_A = (0+1+1+2+0)/5 = 0.8\)
- ラインB:\(\bar{Z}_B = (2+2+0+1+1)/5 = 1.2\)
- ラインC:\(\bar{Z}_C = (2+3+4+5+0)/5 = 2.8\)
全体平均:\(\bar{Z} = (0.8+1.2+2.8)/3 = 1.6\)(加重平均として計算)
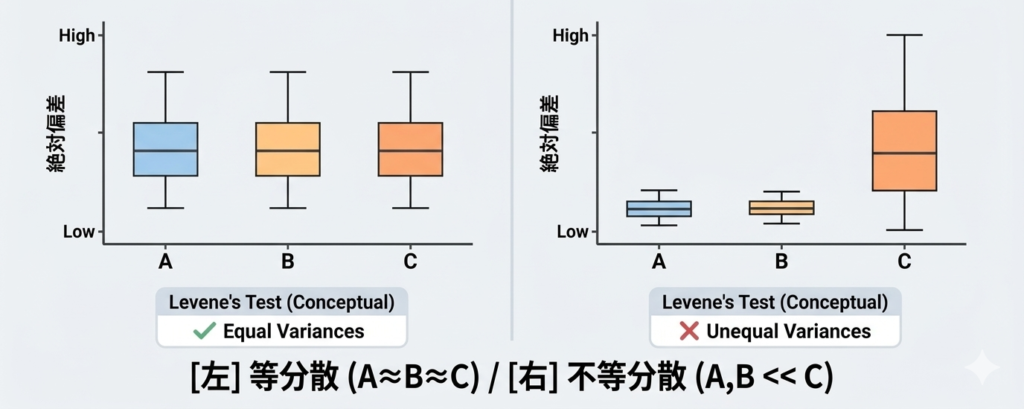
ラインCの絶対偏差の平均がA・Bと比べてかなり大きく、ラインCの分散が他のラインより大きい可能性を示しています。この差が統計的に有意かどうかをF統計量で判断します。
Step 3:F統計量の計算
グループ数を \(k=3\)、全サンプルサイズを \(N=15\) とします。
グループ間変動(SS_between):\[ SS_{between} = \sum_{j=1}^{k} n_j (\bar{Z}_j – \bar{Z})^2 = 5(0.8-1.6)^2 + 5(1.2-1.6)^2 + 5(2.8-1.6)^2 = 5(0.64) + 5(0.16) + 5(1.44) = 3.2+0.8+7.2 = 11.2 \]
グループ内変動(SS_within):\[ SS_{within} = \sum_{j}\sum_{i}(Z_{ij}-\bar{Z}_j)^2 \]
ラインA:\((0-0.8)^2+(1-0.8)^2+(1-0.8)^2+(2-0.8)^2+(0-0.8)^2 = 0.64+0.04+0.04+1.44+0.64 = 2.8\)
ラインB:\((2-1.2)^2+(2-1.2)^2+(0-1.2)^2+(1-1.2)^2+(1-1.2)^2 = 0.64+0.64+1.44+0.04+0.04 = 2.8\)
ラインC:\((2-2.8)^2+(3-2.8)^2+(4-2.8)^2+(5-2.8)^2+(0-2.8)^2 = 0.64+0.04+1.44+4.84+7.84 = 14.8\)\[ SS_{within} = 2.8 + 2.8 + 14.8 = 20.4 \]
F統計量:\[ F = \frac{SS_{between}/(k-1)}{SS_{within}/(N-k)} = \frac{11.2/2}{20.4/12} = \frac{5.6}{1.7} \approx 3.29 \]
自由度 (2, 12) のF分布でp値を確認すると、\(F=3.29\) に対応するp値はおよそ0.07〜0.08程度です。有意水準0.05を下回らないので、等分散の仮説を棄却しない、という結果になります。
ただし、ラインCの散らばりはA・Bより明らかに大きく見えます。こういったグレーゾーンの場合は、Pythonで精度よく計算して判断するのが実務的です。
Pythonでルビーン検定を実装する
scipy.stats.levene() で計算できます。グループを引数として並べるだけです。
from scipy import stats
A = [62, 63, 61, 64, 62]
B = [58, 62, 60, 59, 61]
C = [65, 70, 63, 72, 67]
stat, p_value = stats.levene(A, B, C)
print(f"Levene統計量 = {stat:.4f}")
print(f"p値 = {p_value:.4f}")
if p_value > 0.05:
print("等分散性を棄却しない(分散は等しいと仮定できる)")
else:
print("等分散性を棄却する(ウェルチ法などを検討)")
出力例:
Levene統計量 = 3.2941
p値 = 0.0757
等分散性を棄却しない(分散は等しいと仮定できる)
center='median'(デフォルト)を使うと中央値基準のブラウン-フォーサイス検定になります。平均値基準にする場合は center='mean' を指定します。非正規性に対してはブラウン-フォーサイス(中央値基準)の方がロバストなので、デフォルトのままで使うのが無難です。
等分散でなかった場合の対処法
p値が0.05を下回って等分散を棄却した場合、分析手法を切り替えます。
| 比較する群数 | 等分散が成立 | 等分散が不成立 |
|---|---|---|
| 2群 | スチューデントのt検定 | ウェルチのt検定 |
| 3群以上 | 一元配置分散分析 | ウェルチの分散分析(pingouinライブラリ等を使用) |
| ノンパラ | — | クルスカルワリス検定 |
実務では「等分散かどうかわからない場合はウェルチのt検定を使う」という割り切り方をしている現場も多いです。スチューデントのt検定はウェルチのt検定の特殊ケースでもあるので、最初からウェルチを使えばルビーン検定を省略できると考える立場もあります。どちらのアプローチが適切かは、職場や指導者の方針に合わせて判断してください。
シャピロウイルク検定との組み合わせ
t検定や分散分析の前提確認をまとめると、チェックする項目は2つです。
1つ目がシャピロウイルク検定による正規性の確認、2つ目が今回のルビーン検定による等分散性の確認です。両方をPythonで実施するコードをまとめておきます。
from scipy import stats
groups = {"A": A, "B": B, "C": C}
# 正規性の確認(各グループ)
print("=== シャピロウイルク検定(正規性)===")
for name, data in groups.items():
stat, p = stats.shapiro(data)
result = "棄却しない" if p > 0.05 else "棄却"
print(f"グループ{name}: W={stat:.4f}, p={p:.4f} → {result}")
# 等分散性の確認
print("\n=== ルビーン検定(等分散性)===")
stat, p = stats.levene(*groups.values())
result = "棄却しない" if p > 0.05 else "棄却"
print(f"Levene統計量={stat:.4f}, p={p:.4f} → {result}")
この前提確認を実施した上で、Pythonで分散分析を実行する、というのが一連の流れです。
まとめ
ルビーン検定でやることは、「各データを中央値からの絶対偏差に変換→F統計量を計算→p値が0.05を超えるか確認」という流れです。Pythonなら scipy.stats.levene() 一行で済みます。
個人的には、分析の前提確認にかける時間はなるべく短くしたいので、Pythonのコードに正規性・等分散性の確認セットを書いておいて毎回使い回すようにしています。前提が崩れていたら手法を切り替えるだけなので、確認するハードルは思ったより低いです。
