実験は何回やれば十分ですか?
「この改善実験、最低何個のサンプルを取ればいいですか?」
品質管理部門やR&Dの現場では、統計検定を使うたびにこの質問が上がります。少なすぎると統計的な信頼性が下がるし、多すぎるとコストがかかってしまう。では、必要なサンプルサイズ(n数)は、どうやって決めるのか。
答えは「統計的な効果量と、検定に求める精度から逆算する」というものです。この記事では、t検定や分散分析を使う前に、サンプルサイズを決める方法を、製造業の実例を交えながら解説します。
サンプルサイズを決める3つの要素
サンプルサイズは、以下の3つの要素によって決まります。
- 効果量(effect size):検出したい差や関係の大きさ
- 有意水準(α):第1種の誤り(偽陽性)の許容率。通常は0.05
- 検出力(1-β):実際に効果がある場合にそれを検出できる確率。通常は0.80や0.90を目指す
このうち、最も重要なのが「効果量」です。効果量が大きいほど、少ないサンプルでも検定の結果が出やすくなります。逆に微小な差を検出したければ、膨大なサンプルが必要になります。
効果量(Cohen’s d)とは
効果量とは、グループ間の差が「どの程度大きいか」を標準化した値です。最も一般的なのは、Cohen’s d という指標です。
2つのグループの平均値を比較する場合、Cohen’s d は以下の式で計算されます。\[ d = \frac{\mu_1 – \mu_2}{\sigma} \]
ここで、\( \mu_1 \) と \( \mu_2 \) はそれぞれのグループの平均値、\( \sigma \) は共通の標準偏差です。
具体的な解釈は以下の表を参照してください。
| 効果量 d | 解釈 | 実例 |
|---|---|---|
| 0.2 | 小さい | 専門家でないと気づかないレベルの差 |
| 0.5 | 中程度 | 注意深く見ると分かる差 |
| 0.8 | 大きい | 一目で分かる明らかな差 |
t検定に必要なサンプルサイズの計算
例題:収率改善実験
製造業での典型的なシナリオを例に取りましょう。
現工程の平均収率は 80% で、標準偏差は 4% です。改善案を導入して、収率を 83% に上げたいと考えています。
- 帰無仮説:\( H_0: \mu = 80 \)
- 対立仮説:\( H_1: \mu \neq 80 \)(両側検定)
- 希望する検出力:80%(つまり β = 0.20)
- 有意水準:α = 0.05
まず、効果量を計算します。\[ d = \frac{83 – 80}{4} = \frac{3}{4} = 0.75 \]
効果量 d = 0.75 は「中程度から大きい」範囲です。これは業界的にも現実的な差のレベルです。
簡略計算式
2標本のt検定(両側検定)で必要なサンプルサイズは、以下の近似式で求められます。\[ n = \frac{2(z_{\alpha/2} + z_{\beta})^2}{d^2} \]
ここで:
- \( z_{\alpha/2} \) = 有意水準 α/2 の標準正規分布の上側確率点(α = 0.05 なら 1.96)
- \( z_{\beta} \) = 検出力 1-β の標準正規分布の上側確率点(β = 0.20 なら 0.84)
- \( d \) = 効果量
代入すると:\[ n = \frac{2(1.96 + 0.84)^2}{0.75^2} = \frac{2 \times (2.80)^2}{0.5625} = \frac{2 \times 7.84}{0.5625} \approx 27.9 \]
したがって、各グループに最低 28 個のサンプルが必要です。
改善案と現行案を比較する場合、n = 28 で両側検定を実施すれば、α = 0.05、検出力 80% の条件を満たします。
片側検定の場合
「改善案がより良いことを示したい」という片側検定であれば、サンプルサイズはもう少し少なくて済みます。
片側検定では \( z_{\alpha} = 1.645 \)(α = 0.05)になるため:\[ n = \frac{2(1.645 + 0.84)^2}{0.75^2} = \frac{2 \times (2.485)^2}{0.5625} \approx 22.0 \]
つまり、各グループに 22 個あれば充分です。
一元配置分散分析のサンプルサイズ
複数の条件を同時に比較する場合(例えば、3種類の改善案の効果比較)は、一元配置分散分析を使います。
効果量 f
分散分析では、効果量として Cohen’s f を使用します。これは以下のように定義されます。\[ f = \sqrt{\frac{\sum n_i (\mu_i – \bar{\mu})^2}{k \sigma^2}} \]
簡単な目安は以下の通りです。
- f = 0.10:小さい効果
- f = 0.25:中程度の効果
- f = 0.40:大きい効果
計算例
3つの異なる製造条件の収率を比較するとします。
- グループ数:k = 3
- 効果量:f = 0.25(中程度)
- 有意水準:α = 0.05
- 検出力:0.80
この場合、各グループに約 36 個のサンプルが必要になります。(詳細な計算は一元配置分散分析の記事を参照)
Pythonで自動計算する
毎回手計算をするのは面倒です。Pythonの statsmodels ライブラリを使えば、一瞬で必要なサンプルサイズが求められます。
t検定のサンプルサイズ計算
from statsmodels.stats.power import TTestIndPower
import numpy as np
# t検定(2標本独立、両側検定)
analysis = TTestIndPower()
# 必要なサンプルサイズを計算
effect_size = 0.75 # Cohen's d
alpha = 0.05 # 有意水準
power = 0.80 # 検出力
n = analysis.solve_power(effect_size=effect_size, alpha=alpha,
power=power, alternative='two-sided')
print(f'必要サンプルサイズ(各群): {n:.1f} → {int(np.ceil(n))} 個')
実行すると:
必要サンプルサイズ(各群): 27.9 → 28 個
計算式での結果と一致しました。
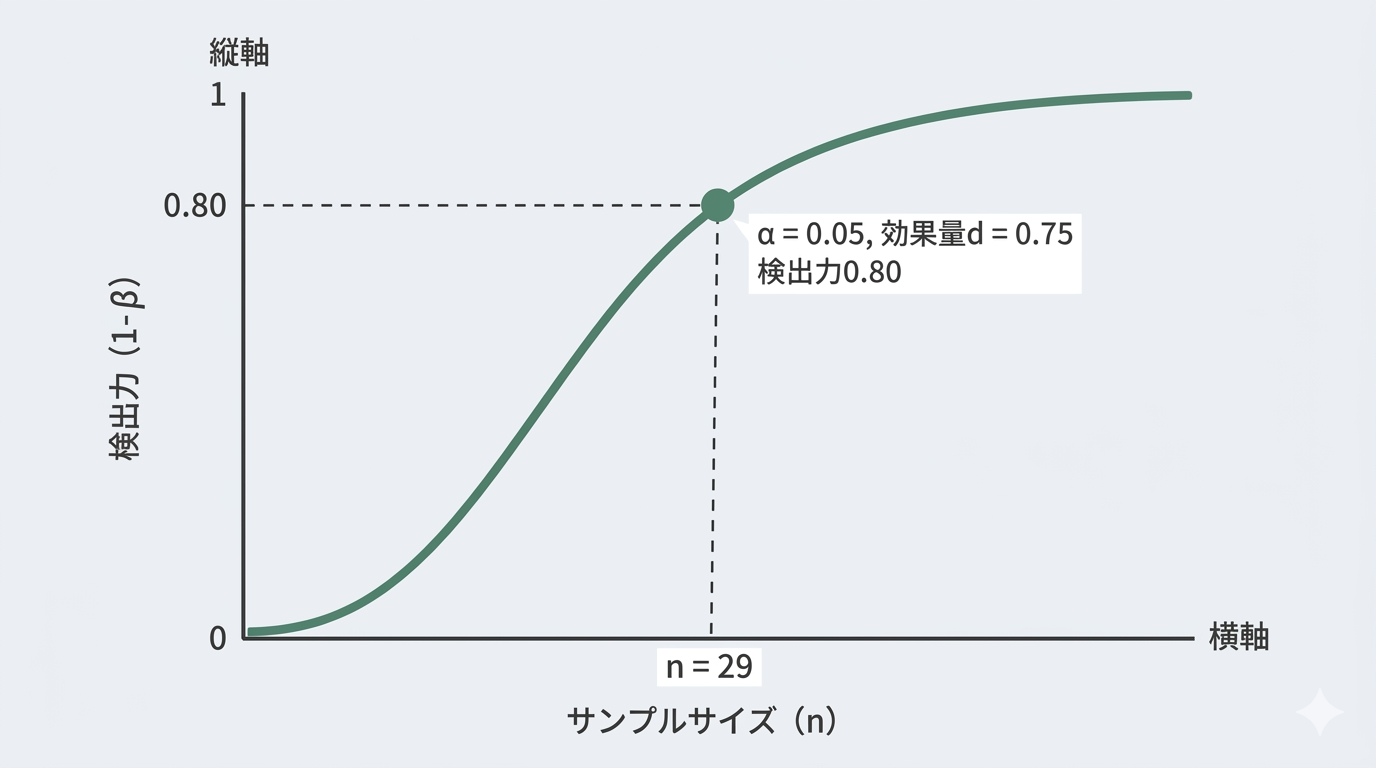
検出力曲線を描画する
サンプルサイズを増やすと検出力がどう上がるか、可視化することも便利です。
import matplotlib.pyplot as plt
# サンプルサイズのレンジ
ns = np.arange(5, 80)
# 各サンプルサイズでの検出力を計算
powers = [analysis.solve_power(effect_size=0.75, alpha=0.05,
nobs1=n, alternative='two-sided') for n in ns]
# 描画
plt.figure(figsize=(10, 6))
plt.plot(ns, powers, linewidth=2, color='#5a8f7b', label='d=0.75')
plt.axhline(y=0.80, color='#333333', linestyle='--', linewidth=1, label='検出力=0.80')
plt.axvline(x=28, color='#c9a961', linestyle='--', linewidth=1, label='n=28')
plt.xlabel('サンプルサイズ (各群)', fontsize=12)
plt.ylabel('検出力', fontsize=12)
plt.title('t検定のサンプルサイズと検出力', fontsize=14, fontweight='bold')
plt.legend()
plt.grid(True, alpha=0.3)
plt.ylim(0, 1)
plt.tight_layout()
plt.show()
一元配置分散分析のサンプルサイズ計算
from statsmodels.stats.power import FTestAnovaPower
# 分散分析(3グループ比較)
anova_analysis = FTestAnovaPower()
effect_size = 0.25 # Cohen's f
alpha = 0.05
power = 0.80
k_groups = 3 # グループ数
n_per_group = anova_analysis.solve_power(effect_size=effect_size, alpha=alpha,
power=power, k_groups=k_groups)
print(f'各グループに必要なサンプルサイズ: {n_per_group:.1f} → {int(np.ceil(n_per_group))} 個')
print(f'全体で必要なサンプル数: {int(np.ceil(n_per_group)) * k_groups} 個')
実行結果:
各グループに必要なサンプルサイズ: 35.9 → 36 個
全体で必要なサンプル数: 108 個
サンプルサイズが増やせない場合
現実には、予算や時間の制約で理想的なサンプルサイズが取れないことがあります。その場合は、何を優先するか考える必要があります。
検出力を下げる
検出力を 80% から 70% に落とせば、必要なサンプルサイズも減ります。ただし、実際に効果がある場合に見落とす確率が高まります。
効果量の事前設定を見直す
「ぜひとも検出したい差」を最初から小さく設定すれば、当然サンプルサイズは増えます。逆に「この差なら見落としてもいい」という最小差を設定すれば、サンプルサイズは減ります。
両側から片側へ
「改善案が現行案より良い」という一方向の仮説なら、片側検定にして約 22% 少ないサンプルで済みます。
内部リンク:検定の前提条件を確認する
サンプルサイズを決めたら、実際に検定を行う前に、データが正規分布に従うか、グループ間で等分散か を確認する必要があります。詳しくは仮説検定の考え方と手順や、統計的検定の選び方を参照してください。
また、F検定とt検定の違いも理解しておくと、データに応じた検定の使い分けがスムーズになります。
まとめ
サンプルサイズを決めるポイントをまとめます。
- 効果量が大きいほど、少ないサンプルで十分。逆に微小な差を検出するには膨大なサンプルが必要
- 有意水準(α)と検出力(1-β)は、通常 α = 0.05、検出力 = 0.80 が標準。研究の重要度に応じて調整
- t検定なら d、分散分析なら f という効果量指標を使う
- Pythonの statsmodels を使えば、計算は一瞬。検出力曲線も描画できる
- 現実的な制約がある場合は、優先順位(検出力か、サンプルサイズか)を明確にして判断する
「何個のサンプルが必要ですか?」という質問には、もう「設計段階で統計的に逆算する」という回答ができます。上司や顧客への説明資料にも、この計算プロセスを載せておくと、信頼性が高まります。
サンプルサイズは信頼区間の幅にも直接影響します。信頼区間の計算とn数の関係は信頼区間の求め方|Excelで95%信頼区間を計算する手順でも確認できます。
サンプルサイズの計算には効果量の事前推定が必要です。Cohen’s dやη²の解釈の基準は効果量(Cohen’s d・η²)の求め方で確認できます。
必要なサンプル数が決まったら、母集団から実際にどう抽出するかはサンプリングの種類を参考にしてください。
標準誤差 σ/√n がサンプル数を増やすほど縮む仕組みは、中心極限定理で解説しています。
サンプル数不足で有意差が出ない場合の見極めは有意差が出ないときの確認7項目で解説しています。