

母集団の分布が正規分布に従うことを仮定しない検定法であるノンパラメトリック検定にはいくつかの種類があります。この記事では、データが”2群比較”かつ”対応のない”場合に使用する、ウイルコクソンの順位和検定(マンホイットニーのU検定)について解説します。
ウイルコクソンの順位和検定(マンホイットニーのU検定)とは
ウイルコクソンの順位和検定は、2つの独立したグループ間の中央値に差があるかどうかを検定するノンパラメトリック手法です(マン・ホイットニーU検定と算出方法に違いはありますがp値同じです)。データが正規分布していない場合、サンプルサイズが小さい場合に適した検定方法です。スチューデントのt検定などとは異なり正規分布を仮定しないため、データの平均値ではなくデータの中央値によって有意差を調べる検定手法です。
ウイルコクソンの順位和検定は、データが”2群比較”かつ”対応のない”場合に使用します。”対応のある”データにはウイルコクソンの符号順位和検定を使用します。
ウイルコクソンの順位和検定(マンホイットニーのU検定)の計算手順
以下ウイルコクソンの順位和検定(マンホイットニーのU検定)の実施手順を解説します。
【1】仮説を立てる
- 帰無仮説(H0):群1と群2の2つ群の母集団の順位平均値は”同じ”
- 対立仮説(H1):以下のいずれかの仮説を設定
- 群1の母集団順位平均値は群2の母集団順位平均値より”大きい”
- 群1の母集団順位平均値は群2の母集団順位平均値より”小さい”
- 群1と群2の2群の母集団順位平均値は”異なる”
【2】両側検定、片側検定を決める
対立仮説によって自動的に決まります。
- 群1の母集団順位平均値は群2の母集団順位平均値より”大きい” ⇒ 片側検定(右側検定)
- 群1の母集団順位平均値は群2の母集団順位平均値より”小さい” ⇒ 片側検定(左側検定)
- 群1と群2の2群の母集団順位平均値は”異なる” ⇒ 両側検定
【3】検定統計量を算出
- データのランク付け:全てのデータを昇順に並べ、それぞれに順位を付けます。同じ値には平均の順位を割り当てます。
- ランクの合計:各グループのランクの合計を計算します。
- 検定統計量の計算:ランクの合計から検定統計量Uを計算します。Uは次の式で計算されます。
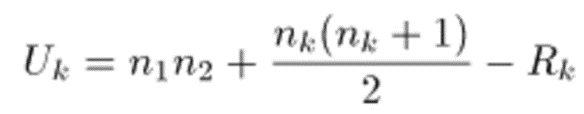
ここで、Rkはそれぞれのグループのランクの合計、nk,n1,n2はそれぞれのグループのサンプルサイズです。Uが最小値を採用します。
【4】p値を算出
- 2群のサンプルサイズいずれも7以下 ⇒ マンホイットニーU検定表適用
- 2群のサンプルサイズいずれかが8以上 ⇒ z分布適用
【5】有意差判定
- p値<有意水準0.05 ⇒ 帰無仮説を棄却し対立仮説を採択。2群の順位平均値に有意差があるといえる
- p値≧有意水準0.05 ⇒ 対立仮説を採択できず、2群の順位平均値に有意差があるといえない
【例題】ウイルコクソンの順位和検定(マンホイットニーのU検定)をやってみよう!
では具体的な例題を使って、ウイルコクソンの順位和検定(マンホイットニーのU検定)を実際に行ってみましょう。
例題:コーヒー豆の比較
あるコーヒーショップが、新しいコーヒー豆(コーヒー豆A)と従来のコーヒー豆(コーヒー豆B)のコーヒーの味を比較するために5人の客に試飲してもらい、10段階でスコアを付けてもらいました。客の評価を基にどちらのコーヒー豆が好まれるかを検定します。
| コーヒー豆A | コーヒー豆B | |
| 客1 | 9 | 4 |
| 客2 | 8 | 5 |
| 客3 | 10 | 6 |
| 客4 | 7 | 5 |
| 客5 | 9 | 6 |
【1】仮説を立てる
・帰無仮説:コーヒー豆Aとコーヒー豆Bの2群の母集団の順位平均値は”同じ”
・対立仮説:コーヒー豆Aとコーヒー豆Bの2群の母集団順位平均値は”異なる”
【2】検定方法
コーヒー豆Aとコーヒー豆Bの2群の母集団順位平均値は”異なる”なので”両側検定”
【3】統計量を算出
1.全てのデータを昇順に並べ、それぞれに順位を付けます。同じ値には平均の順位を割り当てます。
2.A,Bそれぞれのランクの合計を計算します。
3.ランクの合計から検定統計量Uを計算します。

【4】p値を算出
マンホイットニーのU検定の検定表から対応するp値を求めます。今回は”0.0063”です。
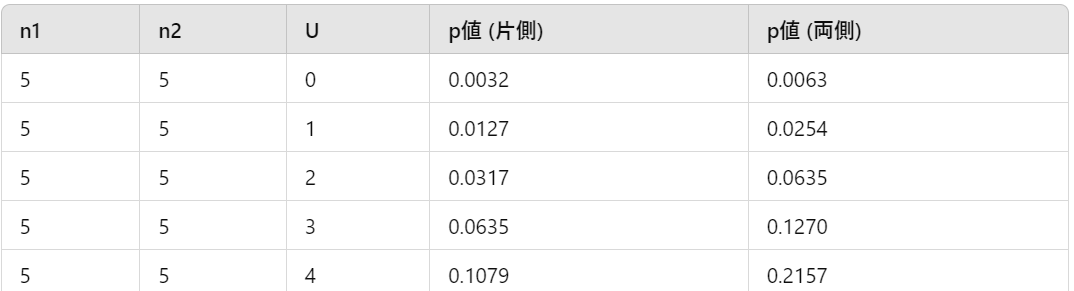
【5】有意差の判定
p値0.0063<有意水準0.05なので、コーヒー豆Aとコーヒー豆Bの味に有意な差があると結論づけられます。客の評価によると、コーヒー豆Aのコーヒーの方が明らかに好まれています。

